Lung-and-colon-cancer-Classification2 /
resnet-paper-code.ipynb
resnet-paper-code.ipynb
import os
import time
import shutil
import pathlib
import itertools
from PIL import Image
# Import data handling tools
import cv2
import numpy as np
import pandas as pd
import seaborn as sns
sns.set_style('darkgrid')
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report, precision_score, recall_score, f1_score
# Import deep learning libraries
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.optimizers import Adam, Adamax
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Activation, Dropout, BatchNormalization, GlobalAveragePooling2D
from tensorflow.keras import regularizers
from tensorflow.keras.callbacks import ModelCheckpoint, EarlyStopping, ReduceLROnPlateau
from tensorflow.keras.applications import DenseNet121,InceptionV3,ResNet50
from tensorflow.keras.models import Model
# Ignore warnings
import warnings
warnings.filterwarnings("ignore")
print('Modules loaded')
# Generate data paths with labels
data_dir = '/kaggle/input/lung-and-colon-cancer-histopathological-images/lung_colon_image_set'
filepaths = []
labels = []
folds = os.listdir(data_dir)
# Generate paths and labels
for fold in folds:
foldpath = os.path.join(data_dir, fold)
flist = os.listdir(foldpath)
for f in flist:
f_path = os.path.join(foldpath, f)
filelist = os.listdir(f_path)
for file in filelist:
fpath = os.path.join(f_path, file)
filepaths.append(fpath)
if f == 'colon_aca':
labels.append('Colon Adenocarcinoma')
elif f == 'colon_n':
labels.append('Colon Benign Tissue')
elif f == 'lung_aca':
labels.append('Lung Adenocarcinoma')
elif f == 'lung_n':
labels.append('Lung Benign Tissue')
elif f == 'lung_scc':
labels.append('Lung Squamous Cell Carcinoma')
# Concatenate data paths with labels into a DataFrame
df = pd.DataFrame({'filepaths': filepaths, 'labels': labels})
# Split dataset into train, validation, and test sets
train_df, temp_df = train_test_split(df, train_size=0.8, stratify=df['labels'], random_state=42)
valid_df, test_df = train_test_split(temp_df, train_size=0.5, stratify=temp_df['labels'], random_state=42)
# Define image size, channels, and batch size
batch_size = 64
img_size = (224, 224)
channels = 3
img_shape = (img_size[0], img_size[1], channels)
# Create ImageDataGenerator for training and validation
train_datagen = ImageDataGenerator()
valid_datagen = ImageDataGenerator()
train_gen = train_datagen.flow_from_dataframe(train_df, x_col='filepaths', y_col='labels',
target_size=img_size, class_mode='categorical',
batch_size=batch_size, shuffle=True)
valid_gen = valid_datagen.flow_from_dataframe(valid_df, x_col='filepaths', y_col='labels',
target_size=img_size, class_mode='categorical',
batch_size=batch_size, shuffle=True)
test_gen = valid_datagen.flow_from_dataframe(test_df, x_col='filepaths', y_col='labels',
target_size=img_size, class_mode='categorical',
batch_size=batch_size, shuffle=False)
# Get class names
num_classes = len(train_gen.class_indices)
# Define the model
#base_model = DenseNet121(input_shape=img_shape, include_top=False, weights='imagenet')
#base_model = InceptionV3(input_shape=img_shape, include_top=False, weights='imagenet')
base_model = ResNet50(input_shape=img_shape, include_top=False, weights='imagenet')
#base_model = DenseNet121(input_shape=img_shape, include_top=False, weights='imagenet')
base_model.trainable = True
x = base_model.output
x = GlobalAveragePooling2D()(x)
x = Dense(256, activation='relu')(x)
predictions = Dense(num_classes, activation='softmax')(x)
model_DenseNet = Model(inputs=base_model.input, outputs=predictions)
# Compile the model
model_DenseNet.compile(optimizer=Adamax(learning_rate=0.001), loss='categorical_crossentropy', metrics=['accuracy'])
# Define callbacks
callbacks = [
ModelCheckpoint(filepath='best_model.keras', monitor='val_loss', save_best_only=True, verbose=1),
EarlyStopping(monitor='val_loss', patience=5, restore_best_weights=True, verbose=1),
ReduceLROnPlateau(monitor='val_loss', factor=0.2, patience=3, min_lr=1e-6, verbose=1)
]
# Helper function to calculate metrics
def calculate_metrics(generator, model):
preds = model.predict(generator)
y_true = generator.classes
y_pred = np.argmax(preds, axis=1)
precision = precision_score(y_true, y_pred, average='weighted')
recall = recall_score(y_true, y_pred, average='weighted')
f1 = f1_score(y_true, y_pred, average='weighted')
return precision, recall, f1
# Train the model and calculate metrics for each epoch
class MetricsCallback(tf.keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs=None):
# Training metrics
train_precision, train_recall, train_f1 = calculate_metrics(train_gen, self.model)
print(f'Epoch {epoch+1} Training Precision: {train_precision:.4f}, Recall: {train_recall:.4f}, F1 Score: {train_f1:.4f}')
# Validation metrics
val_precision, val_recall, val_f1 = calculate_metrics(valid_gen, self.model)
print(f'Epoch {epoch+1} Validation Precision: {val_precision:.4f}, Recall: {val_recall:.4f}, F1 Score: {val_f1:.4f}')
# Measure training time
start_time = time.time()
# Train the model with the custom metrics callback
history = model_DenseNet.fit(train_gen, validation_data=valid_gen, epochs=20, callbacks=[MetricsCallback()] + callbacks)
end_time = time.time()
training_time = end_time - start_time
print(f'Total Training Time: {training_time:.2f} seconds')
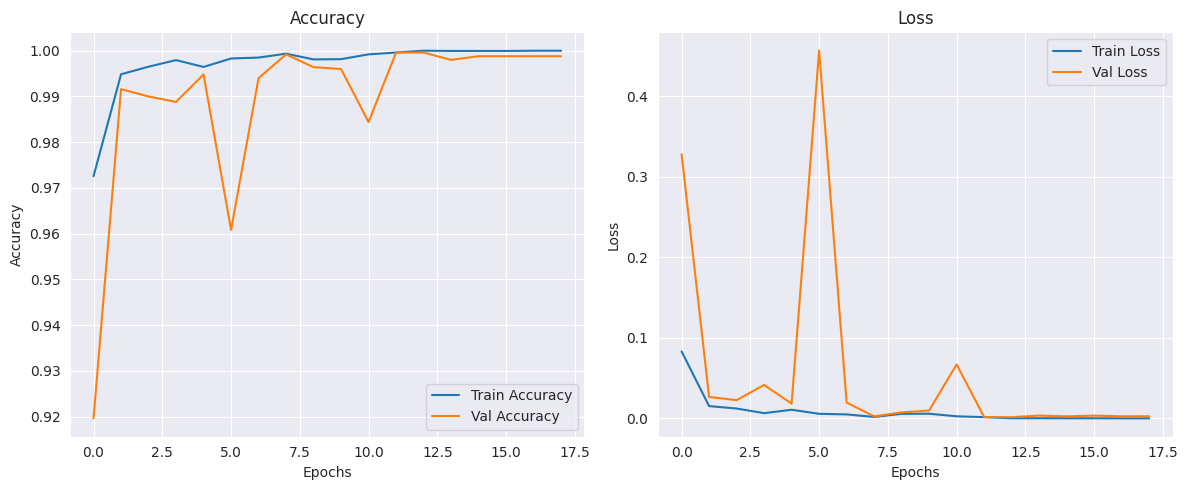
# Plot training history (accuracy and loss)
plt.figure(figsize=(12, 5))
# Plot accuracy
plt.subplot(1, 2, 1)
plt.plot(history.history['accuracy'], label='Train Accuracy')
plt.plot(history.history['val_accuracy'], label='Val Accuracy')
plt.title('Accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
# Plot loss
plt.subplot(1, 2, 2)
plt.plot(history.history['loss'], label='Train Loss')
plt.plot(history.history['val_loss'], label='Val Loss')
plt.title('Loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.tight_layout()
plt.show()
# Measure testing time
start_time = time.time()
# Evaluate on the test set
test_loss, test_acc = model_DenseNet.evaluate(test_gen)
end_time = time.time()
testing_time = end_time - start_time
print(f'Test Accuracy: {test_acc:.4f}')
print(f'Total Testing Time: {testing_time:.2f} seconds')
# Final metrics on the test set
test_precision, test_recall, test_f1 = calculate_metrics(test_gen, model_DenseNet)
print(f'Test Precision: {test_precision:.4f}, Recall: {test_recall:.4f}, F1 Score: {test_f1:.4f}')
Modules loaded
Found 20000 validated image filenames belonging to 5 classes.
Found 2500 validated image filenames belonging to 5 classes.
Found 2500 validated image filenames belonging to 5 classes.
Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/resnet/resnet50_weights_tf_dim_ordering_tf_kernels_notop.h5
[1m94765736/94765736[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 0us/step
Epoch 1/20
WARNING: All log messages before absl::InitializeLog() is called are written to STDERR
I0000 00:00:1727872134.215158 67 service.cc:145] XLA service 0x7b36b4003180 initialized for platform CUDA (this does not guarantee that XLA will be used). Devices:
I0000 00:00:1727872134.215219 67 service.cc:153] StreamExecutor device (0): Tesla P100-PCIE-16GB, Compute Capability 6.0
I0000 00:00:1727872164.157488 67 device_compiler.h:188] Compiled cluster using XLA! This line is logged at most once for the lifetime of the process.
[1m313/313[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m100s[0m 309ms/step
Epoch 1 Training Precision: 0.2069, Recall: 0.2079, F1 Score: 0.2050
[1m40/40[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m13s[0m 328ms/step
Epoch 1 Validation Precision: 0.1897, Recall: 0.1896, F1 Score: 0.1865
Epoch 1: val_loss improved from inf to 0.32810, saving model to best_model.keras
[1m313/313[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m387s[0m 1s/step - accuracy: 0.9385 - loss: 0.1924 - val_accuracy: 0.9196 - val_loss: 0.3281 - learning_rate: 0.0010
Epoch 2/20
[1m313/313[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m91s[0m 291ms/step
Epoch 2 Training Precision: 0.1999, Recall: 0.1999, F1 Score: 0.1999
[1m40/40[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m12s[0m 299ms/step
Epoch 2 Validation Precision: 0.2011, Recall: 0.2012, F1 Score: 0.2011
Epoch 2: val_loss improved from 0.32810 to 0.02662, saving model to best_model.keras
[1m313/313[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m216s[0m 684ms/step - accuracy: 0.9951 - loss: 0.0154 - val_accuracy: 0.9916 - val_loss: 0.0266 - learning_rate: 0.0010
Epoch 3/20
[1m313/313[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m91s[0m 290ms/step
Epoch 3 Training Precision: 0.1952, Recall: 0.1951, F1 Score: 0.1951
[1m40/40[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m12s[0m 306ms/step
Epoch 3 Validation Precision: 0.2044, Recall: 0.2044, F1 Score: 0.2044
Epoch 3: val_loss improved from 0.02662 to 0.02261, saving model to best_model.keras
[1m313/313[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m217s[0m 686ms/step - accuracy: 0.9968 - loss: 0.0132 - val_accuracy: 0.9900 - val_loss: 0.0226 - learning_rate: 0.0010
Epoch 4/20
[1m313/313[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m93s[0m 297ms/step
Epoch 4 Training Precision: 0.2011, Recall: 0.2010, F1 Score: 0.2010
[1m40/40[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m12s[0m 305ms/step
Epoch 4 Validation Precision: 0.2169, Recall: 0.2172, F1 Score: 0.2170
Epoch 4: val_loss did not improve from 0.02261
[1m313/313[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m217s[0m 687ms/step - accuracy: 0.9985 - loss: 0.0051 - val_accuracy: 0.9888 - val_loss: 0.0415 - learning_rate: 0.0010
Epoch 5/20
[1m313/313[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m94s[0m 300ms/step
Epoch 5 Training Precision: 0.1981, Recall: 0.1981, F1 Score: 0.1981
[1m40/40[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m12s[0m 293ms/step
Epoch 5 Validation Precision: 0.2008, Recall: 0.2008, F1 Score: 0.2008
Epoch 5: val_loss improved from 0.02261 to 0.01833, saving model to best_model.keras
[1m313/313[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m220s[0m 696ms/step - accuracy: 0.9977 - loss: 0.0070 - val_accuracy: 0.9948 - val_loss: 0.0183 - learning_rate: 0.0010
Epoch 6/20
[1m313/313[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m94s[0m 300ms/step
Epoch 6 Training Precision: 0.1949, Recall: 0.1951, F1 Score: 0.1947
[1m40/40[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m12s[0m 299ms/step
Epoch 6 Validation Precision: 0.1890, Recall: 0.1892, F1 Score: 0.1886
Epoch 6: val_loss did not improve from 0.01833
[1m313/313[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m217s[0m 687ms/step - accuracy: 0.9982 - loss: 0.0061 - val_accuracy: 0.9608 - val_loss: 0.4567 - learning_rate: 0.0010
Epoch 7/20
[1m313/313[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m93s[0m 298ms/step
Epoch 7 Training Precision: 0.1957, Recall: 0.1956, F1 Score: 0.1957
[1m40/40[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m12s[0m 293ms/step
Epoch 7 Validation Precision: 0.1861, Recall: 0.1860, F1 Score: 0.1860
Epoch 7: val_loss did not improve from 0.01833
[1m313/313[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m218s[0m 691ms/step - accuracy: 0.9988 - loss: 0.0045 - val_accuracy: 0.9940 - val_loss: 0.0197 - learning_rate: 0.0010
Epoch 8/20
[1m313/313[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m96s[0m 306ms/step
Epoch 8 Training Precision: 0.1985, Recall: 0.1985, F1 Score: 0.1985
[1m40/40[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m12s[0m 301ms/step
Epoch 8 Validation Precision: 0.2040, Recall: 0.2040, F1 Score: 0.2040
Epoch 8: val_loss improved from 0.01833 to 0.00252, saving model to best_model.keras
[1m313/313[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m222s[0m 702ms/step - accuracy: 0.9992 - loss: 0.0024 - val_accuracy: 0.9992 - val_loss: 0.0025 - learning_rate: 0.0010
Epoch 9/20
[1m313/313[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m94s[0m 299ms/step
Epoch 9 Training Precision: 0.2037, Recall: 0.2037, F1 Score: 0.2037
[1m40/40[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m12s[0m 310ms/step
Epoch 9 Validation Precision: 0.1896, Recall: 0.1896, F1 Score: 0.1896
Epoch 9: val_loss did not improve from 0.00252
[1m313/313[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m222s[0m 703ms/step - accuracy: 0.9981 - loss: 0.0049 - val_accuracy: 0.9964 - val_loss: 0.0074 - learning_rate: 0.0010
Epoch 10/20
[1m313/313[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m93s[0m 298ms/step
Epoch 10 Training Precision: 0.2004, Recall: 0.2004, F1 Score: 0.2004
[1m40/40[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m12s[0m 297ms/step
Epoch 10 Validation Precision: 0.2012, Recall: 0.2012, F1 Score: 0.2012
Epoch 10: val_loss did not improve from 0.00252
[1m313/313[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m221s[0m 701ms/step - accuracy: 0.9975 - loss: 0.0093 - val_accuracy: 0.9960 - val_loss: 0.0098 - learning_rate: 0.0010
Epoch 11/20
[1m313/313[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m94s[0m 301ms/step
Epoch 11 Training Precision: 0.2025, Recall: 0.2025, F1 Score: 0.2024
[1m40/40[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m12s[0m 297ms/step
Epoch 11 Validation Precision: 0.2111, Recall: 0.2120, F1 Score: 0.2114
Epoch 11: val_loss did not improve from 0.00252
Epoch 11: ReduceLROnPlateau reducing learning rate to 0.00020000000949949026.
[1m313/313[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m221s[0m 700ms/step - accuracy: 0.9993 - loss: 0.0020 - val_accuracy: 0.9844 - val_loss: 0.0670 - learning_rate: 0.0010
Epoch 12/20
[1m313/313[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m92s[0m 293ms/step
Epoch 12 Training Precision: 0.1963, Recall: 0.1963, F1 Score: 0.1963
[1m40/40[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m12s[0m 300ms/step
Epoch 12 Validation Precision: 0.1912, Recall: 0.1912, F1 Score: 0.1912
Epoch 12: val_loss improved from 0.00252 to 0.00164, saving model to best_model.keras
[1m313/313[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m218s[0m 689ms/step - accuracy: 0.9990 - loss: 0.0039 - val_accuracy: 0.9996 - val_loss: 0.0016 - learning_rate: 2.0000e-04
Epoch 13/20
[1m313/313[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m94s[0m 299ms/step
Epoch 13 Training Precision: 0.2017, Recall: 0.2017, F1 Score: 0.2017
[1m40/40[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m12s[0m 300ms/step
Epoch 13 Validation Precision: 0.1956, Recall: 0.1956, F1 Score: 0.1956
Epoch 13: val_loss improved from 0.00164 to 0.00147, saving model to best_model.keras
[1m313/313[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m221s[0m 698ms/step - accuracy: 1.0000 - loss: 1.2896e-04 - val_accuracy: 0.9996 - val_loss: 0.0015 - learning_rate: 2.0000e-04
Epoch 14/20
[1m313/313[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m95s[0m 303ms/step
Epoch 14 Training Precision: 0.2039, Recall: 0.2039, F1 Score: 0.2039
[1m40/40[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m12s[0m 293ms/step
Epoch 14 Validation Precision: 0.2069, Recall: 0.2068, F1 Score: 0.2068
Epoch 14: val_loss did not improve from 0.00147
[1m313/313[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m223s[0m 705ms/step - accuracy: 1.0000 - loss: 8.5506e-05 - val_accuracy: 0.9980 - val_loss: 0.0035 - learning_rate: 2.0000e-04
Epoch 15/20
[1m313/313[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m94s[0m 299ms/step
Epoch 15 Training Precision: 0.2013, Recall: 0.2013, F1 Score: 0.2013
[1m40/40[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m12s[0m 299ms/step
Epoch 15 Validation Precision: 0.2060, Recall: 0.2060, F1 Score: 0.2060
Epoch 15: val_loss did not improve from 0.00147
[1m313/313[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m221s[0m 699ms/step - accuracy: 0.9999 - loss: 2.3340e-04 - val_accuracy: 0.9988 - val_loss: 0.0025 - learning_rate: 2.0000e-04
Epoch 16/20
[1m313/313[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m92s[0m 295ms/step
Epoch 16 Training Precision: 0.1987, Recall: 0.1987, F1 Score: 0.1987
[1m40/40[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m12s[0m 293ms/step
Epoch 16 Validation Precision: 0.1924, Recall: 0.1924, F1 Score: 0.1924
Epoch 16: val_loss did not improve from 0.00147
Epoch 16: ReduceLROnPlateau reducing learning rate to 4.0000001899898055e-05.
[1m313/313[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m219s[0m 694ms/step - accuracy: 1.0000 - loss: 9.3563e-05 - val_accuracy: 0.9988 - val_loss: 0.0034 - learning_rate: 2.0000e-04
Epoch 17/20
[1m313/313[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m93s[0m 297ms/step
Epoch 17 Training Precision: 0.1928, Recall: 0.1928, F1 Score: 0.1928
[1m40/40[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m12s[0m 287ms/step
Epoch 17 Validation Precision: 0.2116, Recall: 0.2116, F1 Score: 0.2116
Epoch 17: val_loss did not improve from 0.00147
[1m313/313[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m217s[0m 687ms/step - accuracy: 1.0000 - loss: 5.9183e-05 - val_accuracy: 0.9988 - val_loss: 0.0026 - learning_rate: 4.0000e-05
Epoch 18/20
[1m313/313[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m93s[0m 297ms/step
Epoch 18 Training Precision: 0.1968, Recall: 0.1968, F1 Score: 0.1968
[1m40/40[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m12s[0m 300ms/step
Epoch 18 Validation Precision: 0.1840, Recall: 0.1840, F1 Score: 0.1840
Epoch 18: val_loss did not improve from 0.00147
[1m313/313[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m219s[0m 692ms/step - accuracy: 1.0000 - loss: 4.8361e-05 - val_accuracy: 0.9988 - val_loss: 0.0026 - learning_rate: 4.0000e-05
Epoch 18: early stopping
Restoring model weights from the end of the best epoch: 13.
Total Training Time: 4116.00 seconds
[1m40/40[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m29s[0m 723ms/step - accuracy: 0.9991 - loss: 0.0015
Test Accuracy: 0.9996
Total Testing Time: 30.12 seconds
[1m40/40[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m11s[0m 281ms/step
Test Precision: 0.9996, Recall: 0.9996, F1 Score: 0.9996