# KGLiDS - Linked Data Science Powered by Knowledge Graphs
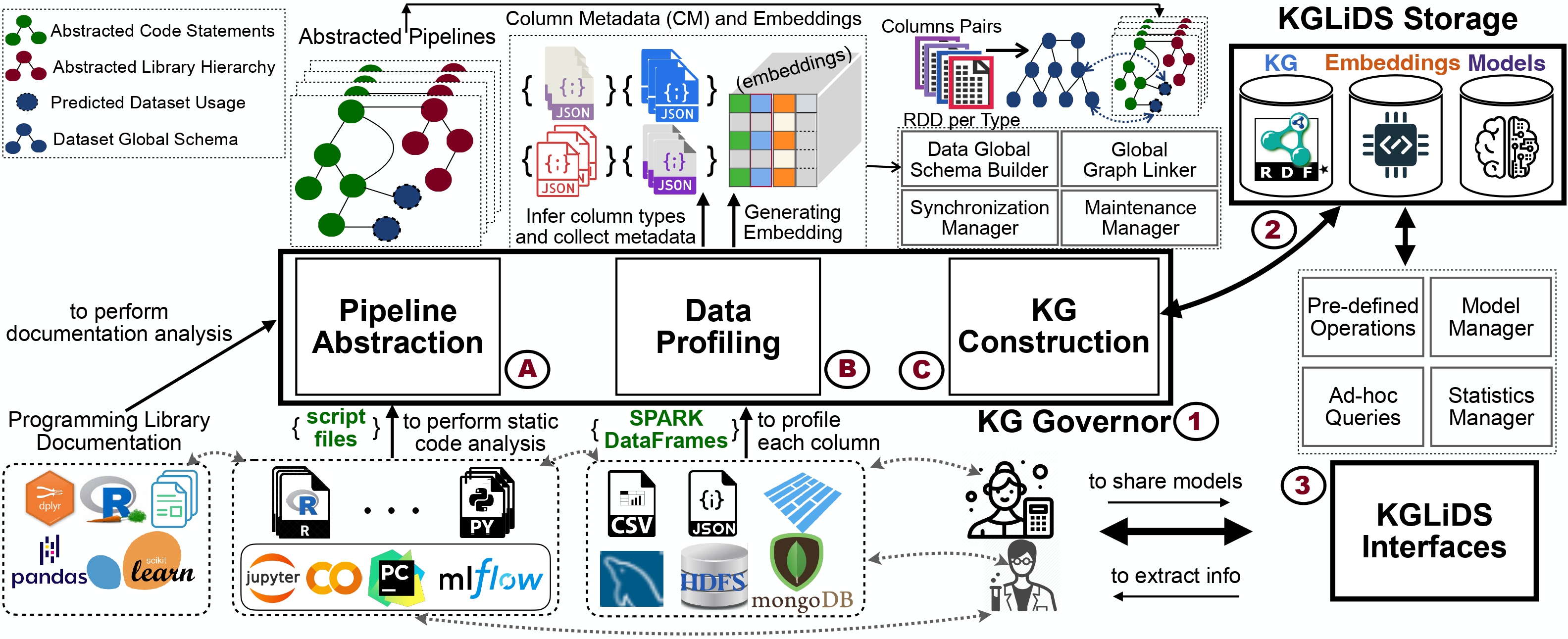
In recent years, we have witnessed a growing interest in data science
not only from academia but particularly from companies investing
in data science platforms to analyze large amounts of data. In this
process, a myriad of data science artifacts, such as datasets and
pipeline scripts, are created. Yet, there has so far been no systematic
attempt to holistically exploit the collected knowledge and expe-
riences that are implicitly contained in the specification of these
pipelines, e.g., compatible datasets, cleansing steps, ML algorithms,
parameters, etc. Instead, data scientists still spend a considerable
amount of their time trying to recover relevant information and
experiences from colleagues, trial and error, lengthy exploration,
etc. In this paper, we therefore propose a novel system (KGLiDS)
that employs machine learning to extract the semantics of data
science pipelines and captures them in a knowledge graph, which
can then be exploited to assist data scientists in various ways. This
abstraction is the key to enable Linked Data Science since it allows
us to share the essence of pipelines between platforms, companies,
and institutions without revealing critical internal information and
instead focusing on the semantics of what is being processed and
how. Our comprehensive evaluation uses thousands of datasets and
more than thirteen thousand pipeline scripts extracted from data
discovery benchmarks and the Kaggle portal, and show that KGLiDS
significantly outperforms state-of-the-art systems on related tasks,
such as datasets and pipeline recommendation.
## Installation
* Clone the `kglids` repo
* Create `kglids` Conda environment (Python 3.8) and install pip requirements.
* Activate the `kglids` environment
```commandline
conda activate kglids
```
## Quickstart
Try the Sample KGLiDS Colab notebook
for a quick hands-on!
Generating the LiDS graph:
* Add the data sources to [config.py](kg_governor/data_profiling/src/config.py):
```python
# sample configuration
# list of data sources to process
data_sources = [DataSource(name='benchmark',
path='/home/projects/sources/kaggle',
file_type='csv')]
```
* Run the [Data profiler](kg_governor/data_profiling/src/main.py)
```commandline
cd kg_governor/data_profiling/src/
python main.py
```
* Run the [Knowledge graph builder](kg_governor/knowledge_graph_construction/src/data_global_schema_builder.py) to generate the data_items graph
```commandline/
cd kg_governor/knowledge_graph_construction/src/
python data_global_schema_builder.py
```
* Run the [Pipeline abstractor](kg_governor/pipeline_abstraction/pipelines_analysis.py) to generate the pipeline named graph(s)
```
cd kg_governor/pipeline_abstraction/
python pipelines_analysis.py
```
Uploading LiDS graph to the graph-engine (we recommend using [Stardog](https://www.stardog.com/)):
* Create a database
Note: enable support for RDF * (example given below) more info [here](https://docs.stardog.com/query-stardog/edge-properties)
```commandline
stardog-admin db create -o edge.properties=true -n Database_name
```
* Add the dataset-graph to the database
```commandline
stardog data add --format turtle Database_name dataset_graph.ttl
```
* Add the pipeline default graph and named-graphs to the database
```commandline
stardog data add --format turtle Database_name default.ttl library.ttl
```
```python
import os
import stardog
database_name = 'Database_name'
connection_details = {
'endpoint': 'http://localhost:5820',
'username': 'admin',
'password': 'admin'}
conn = stardog.Connection(database_name, **connection_details)
conn.begin()
ttl_files = [i for i in os.listdir(graphs_dir) if i.endswith('ttl')]
for ttl in ttl_files:
conn.add(stardog.content.File(graphs_dir + ttl), graph_uri= 'http://kglids.org/pipelineResource/'
conn.commit()
conn.close()
```
Using the KGLiDS APIs:
KGLiDS provides predefined operations in form of python apis that allow seamless integration with a conventional data science pipeline.
Checkout the full list of [KGLiDS APIs](docs/KGLiDS_apis.md)
## LiDS Ontology
To store the created knowledge graph in a standardized and well-structured way,
we developed an ontology for linked data science: the LiDS Ontology.
Checkout [LiDS Ontology](docs/LiDS_ontology.md)!
## Benchmarking
The following benchmark datasets were used to evaluate KGLiDS:
* Dataset Discovery in Data Lakes
* [Smaller Real](https://github.com/alex-bogatu/d3l)
* [Synthetic](https://github.com/RJMillerLab/table-union-search-benchmark)
(more info on data discovery benchmarks [here](https://arxiv.org/pdf/2011.10427.pdf))
* Kaggle
* [`setup_kaggle_data.py`](storage/utils/setup_kaggle_data.py)
## KGLiDS APIs
See the full list of supported APIs [here](docs/KGLiDS_apis.md).
## Citing Our Work
If you find our work useful, please cite it in your research.
## Publicity
This repository is part of our submission. We will make it available to the public research community upon acceptance.
## Questions
For any questions please contact us:
mossad.helali@concordia.ca
shubham.vashisth@concordia.ca
philippe.carrier@concordia.ca
khose@cs.aau.dk
essam.mansour@concordia.ca