## KGLiDS APIs
KGLiDS provides predefined operations in form of python apis that allow seamless integration with a
conventional data science pipeline.
List of all APIs available:
| S.no | API | Description |
|------|---------------------------------------------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 1. | `query()` | Executes ad-hoc queries on fly |
| 2. | `show_graph_info()` | Summarizes the information captured by KGLiDS. Shows:
1. Total number of datasets abstracted
2. Total number of tables abstracted
3. Total number of columns abstracted
4. Total number of pipelines abstracted |
| 3. | `get_datasets_info()` | Shows the number of tables and pipelines per dataset |
| 4. | `get_tables_info()` | Shows all tables alongside their physical file path and dataset |
| 5. | `search_tables_on()` | Searches tables containing specific column names. |
| 6. | `recommend_k_unionable_tables()` | Returns the top k tables that are unionable |
| 7. | `recommend_k_joinable_tables()` | Returns the top k tables that are joinable |
| 8. | `get_path_between_tables()` | Visualizes the paths between a starting table and the target one |
| 9. | `get_pipelines_info()` | Shows the following information for all pipeline:
1. Pipeline name
2. Dataset
3. Author
4. Date written on
5. Number of votes
6. Score |
| 10. | `get_most_recent_pipeline()` | Returns the most recent pipeline |
| 11. | `get_top_k_scoring_pipelines_for_dataset()` | Returns the top k pipeline with the highest score |
| 12. | `search_classifier()` | Shows all the classifiers used for a dataset |
| 13. | `get_hyperparameters()` | Returns the hyperparameter values that were used for a given classifier |
| 14. | `get_top_k_library_used()` | Visualizes the top-k libraries that were used overall or for a given dataset |
| 15. | `get_top_used_libraries()` | Retrieve the top-k libraries used in a particular task. Task here could be:
1. Classification
2. Clustering
3. Regression
4. Visualization |
| 16. | `get_pipelines_calling_libraries()` | Returns a list of pipelines matching the criteria along with other important metadata, such as author, language, etc. |
| 17. | `recommend_transformations()` | Returns the possible set of transformation for tables |
API examples:
1. `kglids.query()`
```python
from api.api import KGLiDS
import pandas as pd
kglids = KGLiDS()
my_custom_query = """
SELECT ?Source
{
?source_id rdf:type kglids:Source ;
schema:name ?source . } """
kglids.query(my_custom_query)
```
| | Source |
|-----|--------|
| 0. | kaggle |
2. `kglids.show_graph_info()`
```python
kglids.show_graph_info()
```
| | Datasets | Tables | Columns | Pipelines |
|-----|----------|--------|---------|-----------|
| 0. | 101 | 969 | 418 | 9502 |
3. `kglids.show_dataset_info()`
```python
kglids.show_dataset_info()
```
| | Dataset | Number_of_tables |
|------|---------------------------------------------------|--------------------|
| 0 | COVID-19 Corona Virus India Dataset | 8 |
| 1 | COVID-19 Dataset | 6 |
| 2 | COVID-19 Healthy Diet Dataset | 5 |
| 3 | COVID-19 Indonesia Dataset | 1 |
| 4 | COVID-19 World Vaccination Progress | 2 |
| ... | ... | ... |
| 96 | uciml.red-wine-quality-cortez-et-al-2009 | 22 |
| 97 | unitednations.international-greenhouse-gas-emi... | 3 |
| 98 | upadorprofzs.testes | 8 |
| 99 | vitaliymalcev.russian-passenger-air-service-20... | 14 |
| 100 | ylchang.coffee-shop-sample-data-1113 | 10 |
4. `kglids.show_table_info()`
```python
kglids.show_table_info()
```
Showing all available table(s):
| | Table | Dataset | Path_to_table |
|------|----------------------------|-------------------------------------------|---------------------------------------------|
| 0 | state_level_daily.csv | COVID-19 Corona Virus India Dataset | /data/datasets/data_lake/COVID-19 Coro... |
| 2 | patients_data.csv | COVID-19 Corona Virus India Dataset | /data/datasets/data_lake/COVID-19 Coro... |
| 3 | nation_level_daily.csv | COVID-19 Corona Virus India Dataset | /data/datasets/data_lake/COVID-19 Coro... |
| ... | ... | ... | ... |
| 414 | 201904 sales reciepts.csv | ylchang.coffee-shop-sample-data-1113 | /data/datasets/data_lake/ylchang.coffe... |
| 415 | sales_outlet.csv | ylchang.coffee-shop-sample-data-1113 | /data/datasets/data_lake/ylchang.coffe... |
| 416 | product.csv | ylchang.coffee-shop-sample-data-1113 | /data/datasets/data_lake/ylchang.coffe... |
| 417 | Dates.csv | ylchang.coffee-shop-sample-data-1113 | /data/datasets/data_lake/ylchang.coffe... |
```python
kglids.get_tables_info(dataset='UK COVID-19 Data')
```
Showing table(s) for 'UK COVID-19 Data' dataset:
| | Table | Dataset | Path_to_table |
|-----|-------------------------------------------------|--------------------|---------------------------------------------|
| 0 | UK_Devolved_Nations_COVID_Dataset.csv | UK COVID-19 Data | /data/datasets/data_lake/UK COVID-19 D... |
| 1 | UK_Local_Authority_UTLA_COVID_Dataset.csv | UK COVID-19 Data | /data/datasets/data_lake/UK COVID-19 D... |
| 2 | England_Regions_COVID_Dataset.csv | UK COVID-19 Data | /data/datasets/data_lake/UK COVID-19 D... |
| 3 | UK_National_Total_COVID_Dataset.csv | UK COVID-19 Data | /data/datasets/data_lake/UK COVID-19 D... |
| 4 | NEW_Official_Population_Data_ONS_mid-2019.csv | UK COVID-19 Data | /data/datasets/data_lake/UK COVID-19 D... |
| 5 | Populations_for_UK_and_Devolved_Nations.csv | UK COVID-19 Data | /data/datasets/data_lake/UK COVID-19 D... |
5. `kglids.show_table_info()`
```python
table_info = kglids.search_tables_on(conditions=[['player', 'club']])
table_info
```
Showing recommendations as per the following conditions:
Condition = [['player', 'club']]
| | Dataset | Table | Number_of_columns | Number_of_rows | Path_to_table |
|------|-------------------------------------------------|--------------------------------|--------------------|-----------------|------------------------------------------------|
| 0 | FIFA 21 complete player dataset | players_21.csv | 106 | 18944 | /data/datasets/data_lake/FIFA 21 compl... |
| 1 | FIFA 21 complete player dataset | players_20.csv | 106 | 18483 | /data/datasets/data_lake/FIFA 21 compl... |
| 2 | FIFA 20 complete player dataset | players_20.csv | 104 | 18278 | /data/datasets/data_lake/FIFA 20 compl... |
| 3 | FIFA 21 complete player dataset | players_19.csv | 106 | 18085 | /data/datasets/data_lake/FIFA 21 compl... |
| 4 | FIFA 20 complete player dataset | players_19.csv | 104 | 17770 | /data/datasets/data_lake/FIFA 20 compl... |
| 5 | FIFA 20 complete player dataset | players_18.csv | 104 | 17592 | /data/datasets/data_lake/FIFA 20 compl... |
| 6 | FIFA 21 complete player dataset | players_18.csv | 106 | 17954 | /data/datasets/data_lake/FIFA 21 compl... |
| 7 | FIFA 21 complete player dataset | players_17.csv | 106 | 17597 | /data/datasets/data_lake/FIFA 21 compl... |
| 8 | FIFA 20 complete player dataset | players_17.csv | 104 | 17009 | /data/datasets/data_lake/FIFA 20 compl... |
| 9 | FIFA 20 complete player dataset | players_16.csv | 104 | 14881 | /data/datasets/data_lake/FIFA 20 compl... |
| 10 | FIFA 21 complete player dataset | players_16.csv | 106 | 15623 | /data/datasets/data_lake/FIFA 21 compl... |
| 11 | FIFA 21 complete player dataset | players_15.csv | 106 | 16155 | /data/datasets/data_lake/FIFA 21 compl... |
| 12 | FIFA 20 complete player dataset | players_15.csv | 104 | 15465 | /data/datasets/data_lake/FIFA 20 compl... |
| 13 | open-source-sports.mens-professional-basketball | basketball_player_allstar.csv | 23 | 1609 | /data/datasets/data_lake/open-source-s... |
| 14 | open-source-sports.mens-professional-basketball | basketball_draft.csv | 11 | 9003 | /data/datasets/data_lake/open-source-s... |
| 15 | open-source-sports.mens-professional-basketball | basketball_awards_players.csv | 6 | 1719 | /data/datasets/data_lake/open-source-s... |
| 16 | FIFA22 OFFICIAL DATASET | FIFA22_official_data.csv | 65 | 16710 | /data/datasets/data_lake/FIFA22 OFFICI... |
| 17 | FIFA22 OFFICIAL DATASET | FIFA21_official_data.csv | 65 | 17108 | /data/datasets/data_lake/FIFA22 OFFICI... |
| 18 | FIFA22 OFFICIAL DATASET | FIFA20_official_data.csv | 65 | 17104 | /data/datasets/data_lake/FIFA22 OFFICI... |
| 19 | FIFA22 OFFICIAL DATASET | FIFA19_official_data.csv | 64 | 17943 | /data/datasets/data_lake/FIFA22 OFFICI... |
| 20 | FIFA22 OFFICIAL DATASET | FIFA18_official_data.csv | 64 | 17927 | /data/datasets/data_lake/FIFA22 OFFICI... |
| 21 | FIFA22 OFFICIAL DATASET | FIFA17_official_data.csv | 63 | 17560 | /data/datasets/data_lake/FIFA22 OFFICI... |
6. `kglids.recommend_k_unionable_tables(table_info: pandas.Series, k: int)`
```python
recommendations_union =kglids.recommend_k_unionable_tables(table_info.iloc[0], k = 5)
recommendations_union
```
Showing the top-5 unionable table recommendations:
| Dataset | Recommended_table | Score | Path_to_table |
|---------|-----------------------------------|------------------|----------------|
| 0 | FIFA 20 complete player dataset | players_20.csv | 1.00 | /data/datasets/data_lake/FIFA 20 compl...|
| 1 | FIFA 20 complete player dataset | players_19.csv | 0.85 | /data/datasets/data_lake/FIFA 20 compl...|
| 2 | FIFA 20 complete player dataset | players_18.csv | 0.85 | /data/datasets/data_lake/FIFA 20 compl...|
| 3 | FIFA 20 complete player dataset | players_17.csv | 0.85 | /data/datasets/data_lake/FIFA 20 compl...|
| 4 | FIFA 20 complete player dataset | players_15.csv | 0.84 | /data/datasets/data_lake/FIFA 20 compl...|
7. `kglids.recommend_k_joinable_tables(table_info: pd.Series, k: int)`
```python
recommendations_join = kglids.kglids.recommend_k_joinable_tables((table_info.iloc[0], k = 2)
recommendations_join
```
Showing the top-2 joinable table recommendations:
| Dataset | Recommended_table | Score | Path_to_table |
|---------|-----------------------------------|-----------------------------|------------------|
| 0 | FIFA 20 complete player dataset | players_20.csv | 1.0 | /data/datasets/data_lake/FIFA 20 compl...|
| 1 | FIFA22 OFFICIAL DATASET | FIFA22_official_data.csv | 0.5 | /data/datasets/data_lake/FIFA22 OFFICI...|
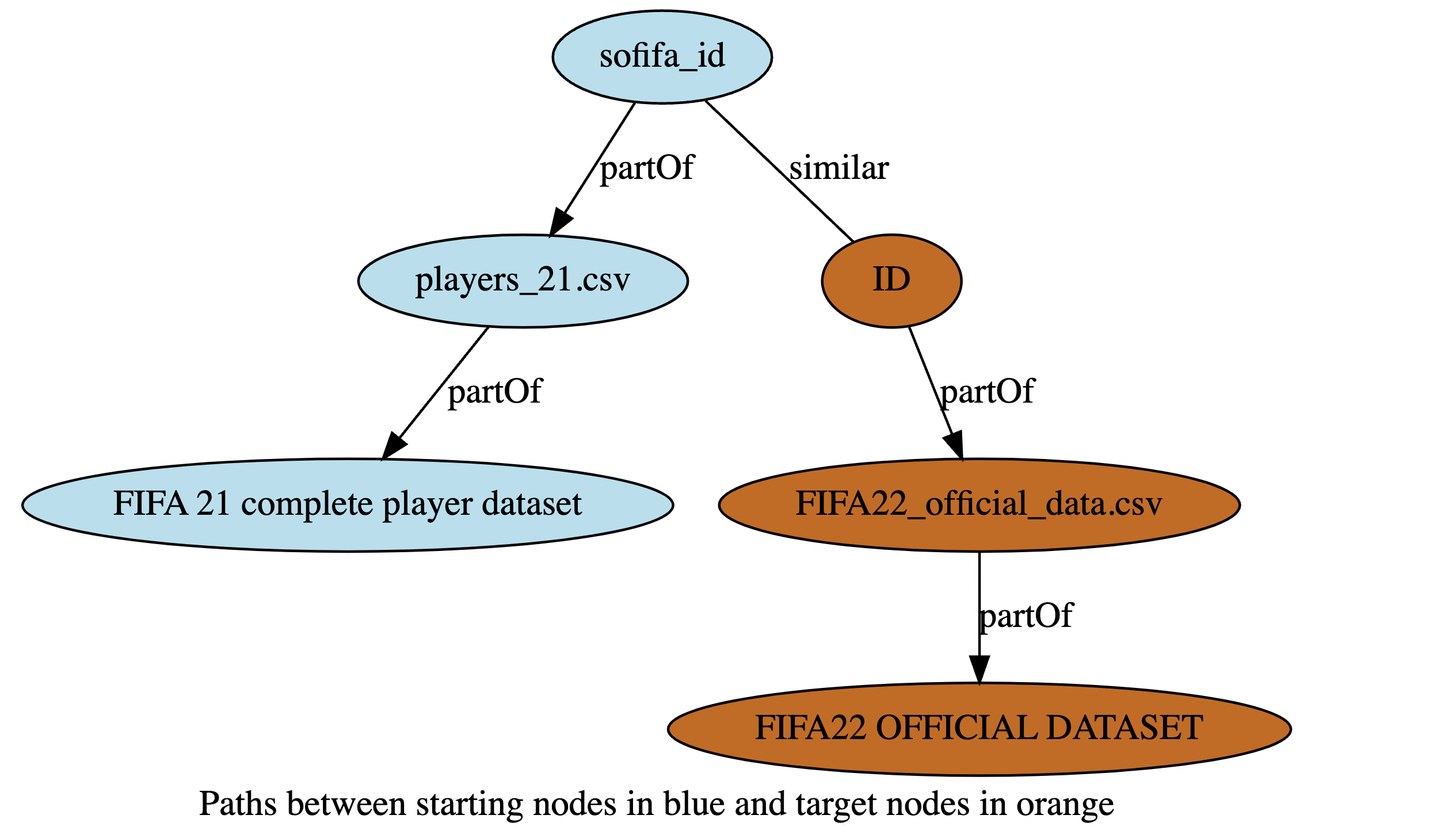
8. `kglids.get_path_between_tables(source_table_info: pd.Series, target_table_info: pd.Series, hops: int)`
```python
kglids.get_path_between_tables(table_info.iloc[0], recommendations_join.iloc[1], hops=1)
```