from pycaret.regression import *
import pandas as pd
%load_ext autoreload
%autoreload 2
df = pd.read_csv('../../data/MiFit/Export data/ACTIVITY/ACTIVITY_1704203167901.csv')
df1 = pd.read_csv('../../data/MiFit/Export data 170420/ACTIVITY/ACTIVITY_1704202151453.csv')
df = pd.concat([df, df1])
df = df.reset_index(drop=True)
# drop date
df = df.drop(columns=['date'])
df.head()
|
steps |
distance |
runDistance |
calories |
| 0 |
1901 |
1279 |
179 |
44 |
| 1 |
995 |
669 |
122 |
24 |
| 2 |
7950 |
5749 |
263 |
182 |
| 3 |
1419 |
955 |
172 |
36 |
| 4 |
1367 |
920 |
109 |
33 |
setup(df, target="calories", verbose=False, session_id=42, html=False)
setup_df = pull()
best_model = compare_models()
compare_df = pull()
Model MAE MSE RMSE \
lr Linear Regression 4.7829 45.0952 6.6513
ridge Ridge Regression 4.7829 45.0952 6.6513
llar Lasso Least Angle Regression 4.7837 45.0909 6.6511
br Bayesian Ridge 4.7844 45.0890 6.6511
lasso Lasso Regression 4.9302 47.7252 6.8417
en Elastic Net 4.9296 47.7112 6.8408
huber Huber Regressor 4.7640 48.5392 6.8969
et Extra Trees Regressor 5.5507 77.8235 8.6873
catboost CatBoost Regressor 5.6985 85.5234 8.9096
gbr Gradient Boosting Regressor 5.7667 81.8716 8.8728
rf Random Forest Regressor 5.7330 82.1203 8.9179
knn K Neighbors Regressor 5.9197 95.4778 9.4639
xgboost Extreme Gradient Boosting 6.1679 107.6687 10.0229
omp Orthogonal Matching Pursuit 6.7567 110.3968 10.3185
dt Decision Tree Regressor 6.3781 114.0464 10.4010
ada AdaBoost Regressor 9.1984 142.5733 11.7862
lightgbm Light Gradient Boosting Machine 6.9481 187.2160 13.1084
lar Least Angle Regression 9.7533 225.9983 14.1739
par Passive Aggressive Regressor 10.0749 269.2730 14.9989
dummy Dummy Regressor 86.8189 10798.3589 102.9788
R2 RMSLE MAPE TT (Sec)
lr 0.9956 0.5003 0.1049 0.004
ridge 0.9956 0.5003 0.1049 0.003
llar 0.9956 0.5000 0.1049 0.004
br 0.9956 0.4994 0.1047 0.003
lasso 0.9954 0.4383 0.0899 0.005
en 0.9954 0.4384 0.0899 0.003
huber 0.9953 0.4554 0.0939 0.004
et 0.9926 0.0725 0.0620 0.022
catboost 0.9923 0.0909 0.0615 0.145
gbr 0.9923 0.1229 0.0612 0.010
rf 0.9922 0.0760 0.0642 0.028
knn 0.9912 0.0781 0.0640 0.005
xgboost 0.9901 0.0937 0.0722 0.010
omp 0.9895 0.2696 0.0793 0.003
dt 0.9894 0.0928 0.0757 0.003
ada 0.9861 0.9246 0.3523 0.009
lightgbm 0.9830 0.0815 0.0693 0.212
lar 0.9797 0.7802 0.2691 0.003
par 0.9750 0.1154 0.0963 0.003
dummy -0.0389 1.8488 3.6105 0.003
plot_model(best_model, plot='feature')
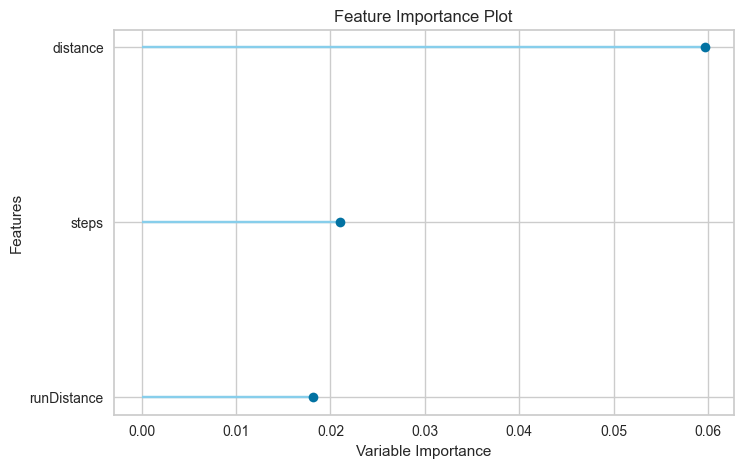
lr = create_model('xgboost')
params = lr.get_params()
| |
MAE |
MSE |
RMSE |
R2 |
RMSLE |
MAPE |
| Fold |
|
|
|
|
|
|
| 0 |
6.3405 |
100.1166 |
10.0058 |
0.9907 |
0.0975 |
0.0732 |
| 1 |
8.6717 |
241.8569 |
15.5518 |
0.9857 |
0.1115 |
0.0898 |
| 2 |
4.0451 |
34.8048 |
5.8996 |
0.9955 |
0.1060 |
0.0688 |
| 3 |
5.2283 |
55.1768 |
7.4281 |
0.9924 |
0.1264 |
0.0867 |
| 4 |
6.9310 |
87.6129 |
9.3602 |
0.9923 |
0.0775 |
0.0644 |
| 5 |
5.8177 |
91.7191 |
9.5770 |
0.9913 |
0.0750 |
0.0598 |
| 6 |
5.3243 |
61.6801 |
7.8537 |
0.9919 |
0.0847 |
0.0742 |
| 7 |
7.1095 |
173.9765 |
13.1900 |
0.9844 |
0.0865 |
0.0697 |
| 8 |
5.7038 |
96.0615 |
9.8011 |
0.9880 |
0.1116 |
0.0880 |
| 9 |
6.5070 |
133.6823 |
11.5621 |
0.9891 |
0.0604 |
0.0469 |
| Mean |
6.1679 |
107.6687 |
10.0229 |
0.9901 |
0.0937 |
0.0722 |
| Std |
1.1967 |
58.4019 |
2.6851 |
0.0032 |
0.0193 |
0.0128 |
from pycaret.classification import *
from pycaret.datasets import get_data
import pandas as pd
df = get_data('diabetes')
df.describe()
---------------------------------------------------------------------------
gaierror Traceback (most recent call last)
File ~/miniconda3/envs/3.10env/lib/python3.8/site-packages/urllib3/connection.py:174, in HTTPConnection._new_conn(self)
173 try:
--> 174 conn = connection.create_connection(
175 (self._dns_host, self.port), self.timeout, **extra_kw
176 )
178 except SocketTimeout:
File ~/miniconda3/envs/3.10env/lib/python3.8/site-packages/urllib3/util/connection.py:72, in create_connection(address, timeout, source_address, socket_options)
68 return six.raise_from(
69 LocationParseError(u"'%s', label empty or too long" % host), None
70 )
---> 72 for res in socket.getaddrinfo(host, port, family, socket.SOCK_STREAM):
73 af, socktype, proto, canonname, sa = res
File ~/miniconda3/envs/3.10env/lib/python3.8/socket.py:918, in getaddrinfo(host, port, family, type, proto, flags)
917 addrlist = []
--> 918 for res in _socket.getaddrinfo(host, port, family, type, proto, flags):
919 af, socktype, proto, canonname, sa = res
gaierror: [Errno 8] nodename nor servname provided, or not known
During handling of the above exception, another exception occurred:
NewConnectionError Traceback (most recent call last)
File ~/miniconda3/envs/3.10env/lib/python3.8/site-packages/urllib3/connectionpool.py:715, in HTTPConnectionPool.urlopen(self, method, url, body, headers, retries, redirect, assert_same_host, timeout, pool_timeout, release_conn, chunked, body_pos, **response_kw)
714 # Make the request on the httplib connection object.
--> 715 httplib_response = self._make_request(
716 conn,
717 method,
718 url,
719 timeout=timeout_obj,
720 body=body,
721 headers=headers,
722 chunked=chunked,
723 )
725 # If we're going to release the connection in ``finally:``, then
726 # the response doesn't need to know about the connection. Otherwise
727 # it will also try to release it and we'll have a double-release
728 # mess.
File ~/miniconda3/envs/3.10env/lib/python3.8/site-packages/urllib3/connectionpool.py:404, in HTTPConnectionPool._make_request(self, conn, method, url, timeout, chunked, **httplib_request_kw)
403 try:
--> 404 self._validate_conn(conn)
405 except (SocketTimeout, BaseSSLError) as e:
406 # Py2 raises this as a BaseSSLError, Py3 raises it as socket timeout.
File ~/miniconda3/envs/3.10env/lib/python3.8/site-packages/urllib3/connectionpool.py:1058, in HTTPSConnectionPool._validate_conn(self, conn)
1057 if not getattr(conn, "sock", None): # AppEngine might not have `.sock`
-> 1058 conn.connect()
1060 if not conn.is_verified:
File ~/miniconda3/envs/3.10env/lib/python3.8/site-packages/urllib3/connection.py:363, in HTTPSConnection.connect(self)
361 def connect(self):
362 # Add certificate verification
--> 363 self.sock = conn = self._new_conn()
364 hostname = self.host
File ~/miniconda3/envs/3.10env/lib/python3.8/site-packages/urllib3/connection.py:186, in HTTPConnection._new_conn(self)
185 except SocketError as e:
--> 186 raise NewConnectionError(
187 self, "Failed to establish a new connection: %s" % e
188 )
190 return conn
NewConnectionError: <urllib3.connection.HTTPSConnection object at 0x29db80fa0>: Failed to establish a new connection: [Errno 8] nodename nor servname provided, or not known
During handling of the above exception, another exception occurred:
MaxRetryError Traceback (most recent call last)
File ~/miniconda3/envs/3.10env/lib/python3.8/site-packages/requests/adapters.py:486, in HTTPAdapter.send(self, request, stream, timeout, verify, cert, proxies)
485 try:
--> 486 resp = conn.urlopen(
487 method=request.method,
488 url=url,
489 body=request.body,
490 headers=request.headers,
491 redirect=False,
492 assert_same_host=False,
493 preload_content=False,
494 decode_content=False,
495 retries=self.max_retries,
496 timeout=timeout,
497 chunked=chunked,
498 )
500 except (ProtocolError, OSError) as err:
File ~/miniconda3/envs/3.10env/lib/python3.8/site-packages/urllib3/connectionpool.py:799, in HTTPConnectionPool.urlopen(self, method, url, body, headers, retries, redirect, assert_same_host, timeout, pool_timeout, release_conn, chunked, body_pos, **response_kw)
797 e = ProtocolError("Connection aborted.", e)
--> 799 retries = retries.increment(
800 method, url, error=e, _pool=self, _stacktrace=sys.exc_info()[2]
801 )
802 retries.sleep()
File ~/miniconda3/envs/3.10env/lib/python3.8/site-packages/urllib3/util/retry.py:592, in Retry.increment(self, method, url, response, error, _pool, _stacktrace)
591 if new_retry.is_exhausted():
--> 592 raise MaxRetryError(_pool, url, error or ResponseError(cause))
594 log.debug("Incremented Retry for (url='%s'): %r", url, new_retry)
MaxRetryError: HTTPSConnectionPool(host='raw.githubusercontent.com', port=443): Max retries exceeded with url: /pycaret/datasets/main/data/common/diabetes.csv (Caused by NewConnectionError('<urllib3.connection.HTTPSConnection object at 0x29db80fa0>: Failed to establish a new connection: [Errno 8] nodename nor servname provided, or not known'))
During handling of the above exception, another exception occurred:
ConnectionError Traceback (most recent call last)
Cell In[19], line 1
----> 1 df = get_data('diabetes')
2 df.describe()
File ~/miniconda3/envs/3.10env/lib/python3.8/site-packages/pycaret/datasets.py:116, in get_data(dataset, folder, save_copy, profile, verbose, address)
114 if os.path.isfile(filename):
115 data = pd.read_csv(filename)
--> 116 elif requests.get(complete_address).status_code == 200:
117 data = pd.read_csv(complete_address)
118 elif dataset in sktime_datasets:
File ~/miniconda3/envs/3.10env/lib/python3.8/site-packages/requests/api.py:73, in get(url, params, **kwargs)
62 def get(url, params=None, **kwargs):
63 r"""Sends a GET request.
64
65 :param url: URL for the new :class:`Request` object.
(...)
70 :rtype: requests.Response
71 """
---> 73 return request("get", url, params=params, **kwargs)
File ~/miniconda3/envs/3.10env/lib/python3.8/site-packages/requests/api.py:59, in request(method, url, **kwargs)
55 # By using the 'with' statement we are sure the session is closed, thus we
56 # avoid leaving sockets open which can trigger a ResourceWarning in some
57 # cases, and look like a memory leak in others.
58 with sessions.Session() as session:
---> 59 return session.request(method=method, url=url, **kwargs)
File ~/miniconda3/envs/3.10env/lib/python3.8/site-packages/requests/sessions.py:589, in Session.request(self, method, url, params, data, headers, cookies, files, auth, timeout, allow_redirects, proxies, hooks, stream, verify, cert, json)
584 send_kwargs = {
585 "timeout": timeout,
586 "allow_redirects": allow_redirects,
587 }
588 send_kwargs.update(settings)
--> 589 resp = self.send(prep, **send_kwargs)
591 return resp
File ~/miniconda3/envs/3.10env/lib/python3.8/site-packages/requests/sessions.py:703, in Session.send(self, request, **kwargs)
700 start = preferred_clock()
702 # Send the request
--> 703 r = adapter.send(request, **kwargs)
705 # Total elapsed time of the request (approximately)
706 elapsed = preferred_clock() - start
File ~/miniconda3/envs/3.10env/lib/python3.8/site-packages/requests/adapters.py:519, in HTTPAdapter.send(self, request, stream, timeout, verify, cert, proxies)
515 if isinstance(e.reason, _SSLError):
516 # This branch is for urllib3 v1.22 and later.
517 raise SSLError(e, request=request)
--> 519 raise ConnectionError(e, request=request)
521 except ClosedPoolError as e:
522 raise ConnectionError(e, request=request)
ConnectionError: HTTPSConnectionPool(host='raw.githubusercontent.com', port=443): Max retries exceeded with url: /pycaret/datasets/main/data/common/diabetes.csv (Caused by NewConnectionError('<urllib3.connection.HTTPSConnection object at 0x29db80fa0>: Failed to establish a new connection: [Errno 8] nodename nor servname provided, or not known'))
df = pd.read_csv('../../data/aw_fb/aw_fb_data.csv')
df = df.drop(['Unnamed: 0', 'X1'], axis=1)
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 6264 entries, 0 to 6263
Data columns (total 18 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 age 6264 non-null int64
1 gender 6264 non-null int64
2 height 6264 non-null float64
3 weight 6264 non-null float64
4 steps 6264 non-null float64
5 hear_rate 6264 non-null float64
6 calories 6264 non-null float64
7 distance 6264 non-null float64
8 entropy_heart 6264 non-null float64
9 entropy_setps 6264 non-null float64
10 resting_heart 6264 non-null float64
11 corr_heart_steps 6264 non-null float64
12 norm_heart 6264 non-null float64
13 intensity_karvonen 6264 non-null float64
14 sd_norm_heart 6264 non-null float64
15 steps_times_distance 6264 non-null float64
16 device 6264 non-null object
17 activity 6264 non-null object
dtypes: float64(14), int64(2), object(2)
memory usage: 881.0+ KB
# df = get_data('diabetes')÷
# group by last column
train_df = df.groupby(df.columns[-1]).head(2)
# drop train_df from df
# df = df.drop(train_df.index)
train_df
|
Number of times pregnant |
Plasma glucose concentration a 2 hours in an oral glucose tolerance test |
Diastolic blood pressure (mm Hg) |
Triceps skin fold thickness (mm) |
2-Hour serum insulin (mu U/ml) |
Body mass index (weight in kg/(height in m)^2) |
Diabetes pedigree function |
Age (years) |
Class variable |
| 0 |
6 |
148 |
72 |
35 |
0 |
33.6 |
0.627 |
50 |
1 |
| 1 |
1 |
85 |
66 |
29 |
0 |
26.6 |
0.351 |
31 |
0 |
| 2 |
8 |
183 |
64 |
0 |
0 |
23.3 |
0.672 |
32 |
1 |
| 3 |
1 |
89 |
66 |
23 |
94 |
28.1 |
0.167 |
21 |
0 |
| 4 |
0 |
137 |
40 |
35 |
168 |
43.1 |
2.288 |
33 |
1 |
|
Number of times pregnant |
Plasma glucose concentration a 2 hours in an oral glucose tolerance test |
Diastolic blood pressure (mm Hg) |
Triceps skin fold thickness (mm) |
2-Hour serum insulin (mu U/ml) |
Body mass index (weight in kg/(height in m)^2) |
Diabetes pedigree function |
Age (years) |
Class variable |
| 0 |
6 |
148 |
72 |
35 |
0 |
33.6 |
0.627 |
50 |
1 |
| 1 |
1 |
85 |
66 |
29 |
0 |
26.6 |
0.351 |
31 |
0 |
| 2 |
8 |
183 |
64 |
0 |
0 |
23.3 |
0.672 |
32 |
1 |
| 3 |
1 |
89 |
66 |
23 |
94 |
28.1 |
0.167 |
21 |
0 |
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
df_aw['activity'] = le.fit_transform(df_aw['activity'])
df_fb['activity'] = le.fit_transform(df_fb['activity'])
df_aw
|
age |
gender |
height |
weight |
steps |
hear_rate |
calories |
distance |
entropy_heart |
entropy_setps |
resting_heart |
corr_heart_steps |
norm_heart |
intensity_karvonen |
sd_norm_heart |
steps_times_distance |
activity |
| 0 |
20 |
1 |
168.0 |
65.4 |
10.771429 |
78.531302 |
0.344533 |
0.008327 |
6.221612 |
6.116349 |
59.000000 |
1.000000 |
19.531302 |
0.138520 |
1.000000 |
0.089692 |
0 |
| 1 |
20 |
1 |
168.0 |
65.4 |
11.475325 |
78.453390 |
3.287625 |
0.008896 |
6.221612 |
6.116349 |
59.000000 |
1.000000 |
19.453390 |
0.137967 |
1.000000 |
0.102088 |
0 |
| 2 |
20 |
1 |
168.0 |
65.4 |
12.179221 |
78.540825 |
9.484000 |
0.009466 |
6.221612 |
6.116349 |
59.000000 |
1.000000 |
19.540825 |
0.138587 |
1.000000 |
0.115287 |
0 |
| 3 |
20 |
1 |
168.0 |
65.4 |
12.883117 |
78.628260 |
10.154556 |
0.010035 |
6.221612 |
6.116349 |
59.000000 |
1.000000 |
19.628260 |
0.139208 |
1.000000 |
0.129286 |
0 |
| 4 |
20 |
1 |
168.0 |
65.4 |
13.587013 |
78.715695 |
10.825111 |
0.010605 |
6.221612 |
6.116349 |
59.000000 |
0.982816 |
19.715695 |
0.139828 |
0.241567 |
0.144088 |
0 |
| ... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
| 3651 |
46 |
0 |
157.5 |
71.4 |
163.000000 |
157.250000 |
0.701500 |
0.075200 |
6.162427 |
5.655310 |
79.421795 |
1.000000 |
77.828205 |
0.822898 |
7.270204 |
12.257600 |
3 |
| 3652 |
46 |
0 |
157.5 |
71.4 |
6.666667 |
157.307692 |
0.701500 |
0.075475 |
6.162427 |
5.655310 |
79.421795 |
1.000000 |
77.885897 |
0.823508 |
1.000000 |
0.503167 |
3 |
| 3653 |
46 |
0 |
157.5 |
71.4 |
6.750000 |
156.250000 |
0.732000 |
0.075695 |
6.162427 |
5.655310 |
79.421795 |
1.000000 |
76.828205 |
0.812325 |
1.000000 |
0.510941 |
3 |
| 3654 |
46 |
0 |
157.5 |
71.4 |
6.791667 |
158.090909 |
0.612500 |
0.077270 |
6.162427 |
5.655310 |
79.421795 |
1.000000 |
78.669114 |
0.831789 |
1.000000 |
0.524792 |
3 |
| 3655 |
46 |
0 |
157.5 |
71.4 |
6.750000 |
157.230769 |
0.671000 |
0.075965 |
6.162427 |
5.655310 |
79.421795 |
1.000000 |
77.808974 |
0.822695 |
1.000000 |
0.512764 |
3 |
3656 rows × 17 columns
df_aw = df[df['device'] == 'apple watch']
df_fb = df[df['device'] == 'fitbit']
df_aw = df_aw.drop('device', axis=1)
df_fb = df_fb.drop('device',axis=1)
df_aw
|
age |
gender |
height |
weight |
steps |
hear_rate |
calories |
distance |
entropy_heart |
entropy_setps |
resting_heart |
corr_heart_steps |
norm_heart |
intensity_karvonen |
sd_norm_heart |
steps_times_distance |
activity |
| 0 |
20 |
1 |
168.0 |
65.4 |
10.771429 |
78.531302 |
0.344533 |
0.008327 |
6.221612 |
6.116349 |
59.000000 |
1.000000 |
19.531302 |
0.138520 |
1.000000 |
0.089692 |
Lying |
| 1 |
20 |
1 |
168.0 |
65.4 |
11.475325 |
78.453390 |
3.287625 |
0.008896 |
6.221612 |
6.116349 |
59.000000 |
1.000000 |
19.453390 |
0.137967 |
1.000000 |
0.102088 |
Lying |
| 2 |
20 |
1 |
168.0 |
65.4 |
12.179221 |
78.540825 |
9.484000 |
0.009466 |
6.221612 |
6.116349 |
59.000000 |
1.000000 |
19.540825 |
0.138587 |
1.000000 |
0.115287 |
Lying |
| 3 |
20 |
1 |
168.0 |
65.4 |
12.883117 |
78.628260 |
10.154556 |
0.010035 |
6.221612 |
6.116349 |
59.000000 |
1.000000 |
19.628260 |
0.139208 |
1.000000 |
0.129286 |
Lying |
| 4 |
20 |
1 |
168.0 |
65.4 |
13.587013 |
78.715695 |
10.825111 |
0.010605 |
6.221612 |
6.116349 |
59.000000 |
0.982816 |
19.715695 |
0.139828 |
0.241567 |
0.144088 |
Lying |
| ... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
| 3651 |
46 |
0 |
157.5 |
71.4 |
163.000000 |
157.250000 |
0.701500 |
0.075200 |
6.162427 |
5.655310 |
79.421795 |
1.000000 |
77.828205 |
0.822898 |
7.270204 |
12.257600 |
Running 7 METs |
| 3652 |
46 |
0 |
157.5 |
71.4 |
6.666667 |
157.307692 |
0.701500 |
0.075475 |
6.162427 |
5.655310 |
79.421795 |
1.000000 |
77.885897 |
0.823508 |
1.000000 |
0.503167 |
Running 7 METs |
| 3653 |
46 |
0 |
157.5 |
71.4 |
6.750000 |
156.250000 |
0.732000 |
0.075695 |
6.162427 |
5.655310 |
79.421795 |
1.000000 |
76.828205 |
0.812325 |
1.000000 |
0.510941 |
Running 7 METs |
| 3654 |
46 |
0 |
157.5 |
71.4 |
6.791667 |
158.090909 |
0.612500 |
0.077270 |
6.162427 |
5.655310 |
79.421795 |
1.000000 |
78.669114 |
0.831789 |
1.000000 |
0.524792 |
Running 7 METs |
| 3655 |
46 |
0 |
157.5 |
71.4 |
6.750000 |
157.230769 |
0.671000 |
0.075965 |
6.162427 |
5.655310 |
79.421795 |
1.000000 |
77.808974 |
0.822695 |
1.000000 |
0.512764 |
Running 7 METs |
3656 rows × 17 columns
df_aw['activity'].unique()
array(['Lying', 'Running 3 METs', 'Running 5 METs', 'Running 7 METs',
'Self Pace walk', 'Sitting'], dtype=object)
def stratified_partition_with_all_values(df, column, n_partitions, partition_id):
# Group the data by the column of interest
grouped = df.groupby(column)
# Initialize empty list to store partitions
partitions = [[] for _ in range(n_partitions)]
# Iterate over groups
for name, group in grouped:
# Randomly shuffle the data within the group
group = group.sample(frac=1).reset_index(drop=True)
# Calculate the number of samples in each partition for this group
samples_per_partition = len(group) // n_partitions
# Distribute the data evenly among partitions, ensuring each partition has all values
for i in range(n_partitions):
start_idx = i * samples_per_partition
end_idx = (i + 1) * samples_per_partition
if i == n_partitions - 1:
end_idx = None # Include remaining samples in the last partition
partition_data = group.iloc[start_idx:end_idx]
partitions[i].append(partition_data)
# Concatenate data frames in each partition
partitions = [pd.concat(partition) for partition in partitions]
return partitions[partition_id].reset_index(drop=True)
df = stratified_partition_with_all_values(df_aw, 'activity', 3, 2)
df['activity'].unique()
array([0, 1, 2, 3, 4, 5])
from sklearn.metrics import log_loss
import numpy as np
exp = ClassificationExperiment()
N_CLIENTS = 3
# df = np.array_split(df, N_CLIENTS)[
# N_CLIENTS-1].reset_index(drop=True)
df = stratified_partition_with_all_values(df_aw, 'activity', 3, 2)
exp.setup(data=df, session_id=42)
exp.add_metric('logloss', 'Log Loss', log_loss,
greater_is_better=False, target="pred_proba")
| |
Description |
Value |
| 0 |
Session id |
42 |
| 1 |
Target |
activity |
| 2 |
Target type |
Multiclass |
| 3 |
Original data shape |
(1222, 17) |
| 4 |
Transformed data shape |
(1222, 17) |
| 5 |
Transformed train set shape |
(855, 17) |
| 6 |
Transformed test set shape |
(367, 17) |
| 7 |
Numeric features |
16 |
| 8 |
Preprocess |
True |
| 9 |
Imputation type |
simple |
| 10 |
Numeric imputation |
mean |
| 11 |
Categorical imputation |
mode |
| 12 |
Fold Generator |
StratifiedKFold |
| 13 |
Fold Number |
10 |
| 14 |
CPU Jobs |
-1 |
| 15 |
Use GPU |
False |
| 16 |
Log Experiment |
False |
| 17 |
Experiment Name |
clf-default-name |
| 18 |
USI |
16c3 |
Name Log Loss
Display Name Log Loss
Score Function <pycaret.internal.metrics.EncodedDecodedLabels...
Scorer make_scorer(log_loss, greater_is_better=False,...
Target pred_proba
Args {}
Greater is Better False
Multiclass True
Custom True
Name: logloss, dtype: object
model_type = {
"linear": [
"lr",
"ridge",
"svm",
"lasso",
"en",
"lar",
"llar",
"omp",
"br",
"ard",
"par",
"ransac",
"tr",
"huber",
"kr",
],
"tree": ["dt"],
"ensemble": [
"rf",
"et",
"gbc",
"gbr",
"xgboost",
"lightgbm",
"catboost",
"ada",
],
}
models = exp.models()
def fil(x):
return False
# add model type to models dataframe based on index
models['model_type'] = models.index.map(lambda x: 'linear' if x in model_type['linear'] else 'tree' if x in model_type['tree'] else 'ensemble' if x in model_type['ensemble'] else 'other')
models
|
Name |
Reference |
Turbo |
model_type |
| ID |
|
|
|
|
| lr |
Logistic Regression |
sklearn.linear_model._logistic.LogisticRegression |
True |
linear |
| knn |
K Neighbors Classifier |
sklearn.neighbors._classification.KNeighborsCl... |
True |
other |
| nb |
Naive Bayes |
sklearn.naive_bayes.GaussianNB |
True |
other |
| dt |
Decision Tree Classifier |
sklearn.tree._classes.DecisionTreeClassifier |
True |
tree |
| svm |
SVM - Linear Kernel |
sklearn.linear_model._stochastic_gradient.SGDC... |
True |
linear |
| rbfsvm |
SVM - Radial Kernel |
sklearn.svm._classes.SVC |
False |
other |
| gpc |
Gaussian Process Classifier |
sklearn.gaussian_process._gpc.GaussianProcessC... |
False |
other |
| mlp |
MLP Classifier |
sklearn.neural_network._multilayer_perceptron.... |
False |
other |
| ridge |
Ridge Classifier |
sklearn.linear_model._ridge.RidgeClassifier |
True |
linear |
| rf |
Random Forest Classifier |
sklearn.ensemble._forest.RandomForestClassifier |
True |
ensemble |
| qda |
Quadratic Discriminant Analysis |
sklearn.discriminant_analysis.QuadraticDiscrim... |
True |
other |
| ada |
Ada Boost Classifier |
sklearn.ensemble._weight_boosting.AdaBoostClas... |
True |
ensemble |
| gbc |
Gradient Boosting Classifier |
sklearn.ensemble._gb.GradientBoostingClassifier |
True |
ensemble |
| lda |
Linear Discriminant Analysis |
sklearn.discriminant_analysis.LinearDiscrimina... |
True |
other |
| et |
Extra Trees Classifier |
sklearn.ensemble._forest.ExtraTreesClassifier |
True |
ensemble |
| xgboost |
Extreme Gradient Boosting |
xgboost.sklearn.XGBClassifier |
True |
ensemble |
| lightgbm |
Light Gradient Boosting Machine |
lightgbm.sklearn.LGBMClassifier |
True |
ensemble |
| catboost |
CatBoost Classifier |
catboost.core.CatBoostClassifier |
True |
ensemble |
| dummy |
Dummy Classifier |
sklearn.dummy.DummyClassifier |
True |
other |
def get_model_weights(model):
"""
Returns model weights (coefficients) if the model supports them.
For ensemble models, it returns feature importances.
"""
model_type = exp._get_model_id(model)
print(model_type)
if model_type in model_type['linear']:
return model.coef_
elif model_type in model_type['tree']:
return model.feature_importances_
else:
raise ValueError(
f"Model type {model_type} does not support weight extraction.")
def set_model_weights(model, weights):
"""
Sets model weights (coefficients) if the model allows it.
For ensemble models, setting weights is not allowed as it doesn't make sense.
"""
model_type = type(model)
if model_type in [LogisticRegression, DecisionTreeClassifier]:
model.coef_ = weights
elif model_type is RandomForestClassifier:
raise ValueError(
"Cannot set weights for ensemble models like RandomForest.")
else:
raise ValueError(
f"Model type {model_type} does not support setting weights.")
# best = exp.compare_models(cross_validation=False)
model = exp.create_model('lightgbm', train_model=True)
# metrics = exp.pull()
| |
Accuracy |
AUC |
Recall |
Prec. |
F1 |
Kappa |
MCC |
Log Loss |
| Fold |
|
|
|
|
|
|
|
|
| 0 |
0.7209 |
0.9184 |
0.7209 |
0.7202 |
0.7174 |
0.6644 |
0.6659 |
1.0252 |
| 1 |
0.6512 |
0.8652 |
0.6512 |
0.6649 |
0.6514 |
0.5786 |
0.5808 |
1.6663 |
| 2 |
0.6744 |
0.9224 |
0.6744 |
0.6974 |
0.6748 |
0.6067 |
0.6111 |
1.0495 |
| 3 |
0.6395 |
0.9045 |
0.6395 |
0.6445 |
0.6385 |
0.5654 |
0.5666 |
1.1714 |
| 4 |
0.6628 |
0.8817 |
0.6628 |
0.6739 |
0.6609 |
0.5945 |
0.5968 |
1.3829 |
| 5 |
0.6118 |
0.8743 |
0.6118 |
0.6038 |
0.6018 |
0.5309 |
0.5330 |
1.5517 |
| 6 |
0.7059 |
0.9091 |
0.7059 |
0.7086 |
0.7036 |
0.6449 |
0.6466 |
1.1767 |
| 7 |
0.7059 |
0.9154 |
0.7059 |
0.7191 |
0.7033 |
0.6457 |
0.6488 |
1.1926 |
| 8 |
0.6588 |
0.8973 |
0.6588 |
0.6632 |
0.6595 |
0.5892 |
0.5898 |
1.2476 |
| 9 |
0.7647 |
0.9261 |
0.7647 |
0.7713 |
0.7641 |
0.7158 |
0.7170 |
1.0081 |
| Mean |
0.6796 |
0.9014 |
0.6796 |
0.6867 |
0.6775 |
0.6136 |
0.6156 |
1.2472 |
| Std |
0.0425 |
0.0201 |
0.0425 |
0.0445 |
0.0436 |
0.0514 |
0.0513 |
0.2112 |
model.booster_.dump_model()['feature_importances']
{'age': 504,
'gender': 77,
'height': 462,
'weight': 541,
'steps': 1607,
'hear_rate': 1823,
'calories': 2296,
'distance': 1470,
'entropy_heart': 644,
'entropy_setps': 714,
'resting_heart': 478,
'corr_heart_steps': 1686,
'norm_heart': 1722,
'intensity_karvonen': 1260,
'sd_norm_heart': 1888,
'steps_times_distance': 802}
best.named_parameters()
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
Cell In[75], line 1
----> 1 best.named_parameters()
AttributeError: 'ExtraTreesClassifier' object has no attribute 'named_parameters'
vars(model)
{'boosting_type': 'gbdt',
'objective': None,
'num_leaves': 31,
'max_depth': -1,
'learning_rate': 0.1,
'n_estimators': 100,
'subsample_for_bin': 200000,
'min_split_gain': 0.0,
'min_child_weight': 0.001,
'min_child_samples': 20,
'subsample': 1.0,
'subsample_freq': 0,
'colsample_bytree': 1.0,
'reg_alpha': 0.0,
'reg_lambda': 0.0,
'random_state': 42,
'n_jobs': -1,
'importance_type': 'split',
'_Booster': <lightgbm.basic.Booster at 0x2a066f160>,
'_evals_result': {},
'_best_score': defaultdict(collections.OrderedDict, {}),
'_best_iteration': 0,
'_other_params': {},
'_objective': 'multiclass',
'class_weight': None,
'_class_weight': None,
'_class_map': {0: 0, 1: 1, 2: 2, 3: 3, 4: 4, 5: 5},
'_n_features': 16,
'_n_features_in': 16,
'_classes': array([0, 1, 2, 3, 4, 5], dtype=int8),
'_n_classes': 6,
'_le': LabelEncoder(),
'fitted_': True}
model.get_params()
{'C': 1.0,
'class_weight': None,
'dual': False,
'fit_intercept': True,
'intercept_scaling': 1,
'l1_ratio': None,
'max_iter': 1000,
'multi_class': 'auto',
'n_jobs': None,
'penalty': 'l2',
'random_state': 42,
'solver': 'lbfgs',
'tol': 0.0001,
'verbose': 0,
'warm_start': False}
exp.predict_model(best)
df = exp.pull()
| |
Model |
Accuracy |
AUC |
Recall |
Prec. |
F1 |
Kappa |
MCC |
Log Loss |
| 0 |
CatBoost Classifier |
0.7057 |
0.9274 |
0.7057 |
0.7090 |
0.7061 |
0.6447 |
0.6452 |
0 |
df.iloc[0].to_dict()
# remove model key
{'Model': 'CatBoost Classifier',
'Accuracy': 0.7057,
'AUC': 0.9274,
'Recall': 0.7057,
'Prec.': 0.709,
'F1': 0.7061,
'Kappa': 0.6447,
'MCC': 0.6452,
'Log Loss': 0}
.pop('key', None)
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
File ~/miniconda3/envs/3.10env/lib/python3.8/site-packages/pandas/core/indexes/base.py:3802, in Index.get_loc(self, key, method, tolerance)
3801 try:
-> 3802 return self._engine.get_loc(casted_key)
3803 except KeyError as err:
File ~/miniconda3/envs/3.10env/lib/python3.8/site-packages/pandas/_libs/index.pyx:138, in pandas._libs.index.IndexEngine.get_loc()
File ~/miniconda3/envs/3.10env/lib/python3.8/site-packages/pandas/_libs/index.pyx:165, in pandas._libs.index.IndexEngine.get_loc()
File pandas/_libs/hashtable_class_helper.pxi:5745, in pandas._libs.hashtable.PyObjectHashTable.get_item()
File pandas/_libs/hashtable_class_helper.pxi:5753, in pandas._libs.hashtable.PyObjectHashTable.get_item()
KeyError: 'model'
The above exception was the direct cause of the following exception:
KeyError Traceback (most recent call last)
Cell In[17], line 1
----> 1 del df['model']
File ~/miniconda3/envs/3.10env/lib/python3.8/site-packages/pandas/core/generic.py:4243, in NDFrame.__delitem__(self, key)
4238 deleted = True
4239 if not deleted:
4240 # If the above loop ran and didn't delete anything because
4241 # there was no match, this call should raise the appropriate
4242 # exception:
-> 4243 loc = self.axes[-1].get_loc(key)
4244 self._mgr = self._mgr.idelete(loc)
4246 # delete from the caches
File ~/miniconda3/envs/3.10env/lib/python3.8/site-packages/pandas/core/indexes/base.py:3804, in Index.get_loc(self, key, method, tolerance)
3802 return self._engine.get_loc(casted_key)
3803 except KeyError as err:
-> 3804 raise KeyError(key) from err
3805 except TypeError:
3806 # If we have a listlike key, _check_indexing_error will raise
3807 # InvalidIndexError. Otherwise we fall through and re-raise
3808 # the TypeError.
3809 self._check_indexing_error(key)
KeyError: 'model'
[(f,getattr(best, f)) if getattr(best,f) is not None else None for f in vars(best)]
[None,
('objective', 'multi:softprob'),
None,
None,
None,
None,
None,
('verbosity', 0),
('booster', 'gbtree'),
('tree_method', 'auto'),
None,
None,
None,
None,
None,
None,
None,
None,
None,
None,
None,
None,
('missing', nan),
None,
('random_state', 42),
('n_jobs', -1),
None,
None,
None,
('device', 'cpu'),
None,
('enable_categorical', False),
None,
None,
None,
None,
None,
None,
None,
('kwargs', {'train': True}),
('n_classes_', 6),
('_Booster', <xgboost.core.Booster at 0x2af3e2e20>)]
type(best)
xgboost.sklearn.XGBClassifier
best.get_params()
{'objective': 'multi:softprob',
'base_score': None,
'booster': 'gbtree',
'callbacks': None,
'colsample_bylevel': None,
'colsample_bynode': None,
'colsample_bytree': None,
'device': 'cpu',
'early_stopping_rounds': None,
'enable_categorical': False,
'eval_metric': None,
'feature_types': None,
'gamma': None,
'grow_policy': None,
'importance_type': None,
'interaction_constraints': None,
'learning_rate': None,
'max_bin': None,
'max_cat_threshold': None,
'max_cat_to_onehot': None,
'max_delta_step': None,
'max_depth': None,
'max_leaves': None,
'min_child_weight': None,
'missing': nan,
'monotone_constraints': None,
'multi_strategy': None,
'n_estimators': None,
'n_jobs': -1,
'num_parallel_tree': None,
'random_state': 42,
'reg_alpha': None,
'reg_lambda': None,
'sampling_method': None,
'scale_pos_weight': None,
'subsample': None,
'tree_method': 'auto',
'validate_parameters': None,
'verbosity': 0}
y = exp.y_test
y.unique()
['Running 3 METs', 'Lying', 'Sitting', 'Self Pace walk', 'Running 5 METs', 'Running 7 METs']
Categories (6, object): ['Lying', 'Running 3 METs', 'Running 5 METs', 'Running 7 METs', 'Self Pace walk', 'Sitting']
exp.predict_model(best)
| |
Model |
Accuracy |
AUC |
Recall |
Prec. |
F1 |
Kappa |
MCC |
Log Loss |
| 0 |
Random Forest Classifier |
0.6730 |
0.9080 |
0.6730 |
0.6815 |
0.6750 |
0.6060 |
0.6067 |
0 |
|
age |
gender |
height |
weight |
steps |
hear_rate |
calories |
distance |
entropy_heart |
entropy_setps |
resting_heart |
corr_heart_steps |
norm_heart |
intensity_karvonen |
sd_norm_heart |
steps_times_distance |
activity |
prediction_label |
prediction_score |
| 299 |
25 |
0 |
166.0 |
68.000000 |
106.000000 |
119.000000 |
4.627800 |
0.076830 |
6.175485 |
5.841891 |
77.039764 |
0.175478 |
41.960236 |
0.355715 |
5.314812 |
8.143980 |
Running 3 METs |
Running 3 METs |
0.69 |
| 251 |
23 |
1 |
181.0 |
95.199997 |
70.000000 |
65.290680 |
17.276400 |
0.052720 |
6.259761 |
6.259761 |
56.333332 |
-1.000000 |
8.957345 |
0.063678 |
0.905729 |
3.690367 |
Lying |
Running 5 METs |
0.43 |
| 374 |
23 |
1 |
178.0 |
77.300003 |
4.923810 |
65.304779 |
16.844400 |
0.003682 |
5.943893 |
6.209454 |
55.000000 |
1.000000 |
10.304782 |
0.072569 |
1.474422 |
0.018131 |
Running 3 METs |
Lying |
0.86 |
| 1167 |
25 |
0 |
160.0 |
57.700001 |
342.532471 |
93.000000 |
19.954000 |
0.188781 |
6.142147 |
6.020552 |
78.531303 |
0.741713 |
14.468698 |
0.124228 |
3.095529 |
64.663727 |
Sitting |
Sitting |
0.56 |
| 420 |
29 |
0 |
159.0 |
55.000000 |
119.000000 |
112.059303 |
0.735000 |
0.044840 |
6.209454 |
5.972835 |
80.621513 |
-0.171754 |
31.437786 |
0.284818 |
3.282160 |
5.335960 |
Running 3 METs |
Running 3 METs |
0.88 |
| ... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
| 423 |
46 |
0 |
157.5 |
71.400002 |
64.000000 |
114.284355 |
0.758000 |
0.034200 |
6.162427 |
5.655310 |
79.421791 |
0.882916 |
34.862564 |
0.368611 |
2.931990 |
2.188800 |
Running 3 METs |
Running 3 METs |
0.62 |
| 979 |
31 |
0 |
158.0 |
59.099998 |
3.285714 |
92.000000 |
0.252000 |
0.002497 |
6.195296 |
6.001153 |
84.199997 |
0.258683 |
7.800000 |
0.074427 |
2.623964 |
0.008205 |
Self Pace walk |
Lying |
0.61 |
| 1064 |
19 |
1 |
183.0 |
65.699997 |
29.333334 |
90.920631 |
0.323600 |
0.021813 |
6.303781 |
6.278464 |
34.153847 |
0.205901 |
56.766788 |
0.340234 |
2.041293 |
0.639858 |
Sitting |
Sitting |
0.54 |
| 943 |
22 |
0 |
168.0 |
62.000000 |
566.599976 |
60.333332 |
17.238728 |
0.388998 |
6.075165 |
6.153087 |
56.200001 |
-0.967908 |
4.133333 |
0.029149 |
1.009217 |
220.406265 |
Self Pace walk |
Self Pace walk |
0.52 |
| 284 |
23 |
1 |
178.0 |
77.300003 |
3.670748 |
62.382870 |
18.213600 |
0.002687 |
5.943893 |
6.209454 |
55.000000 |
1.000000 |
7.382869 |
0.051992 |
1.474422 |
0.009863 |
Running 3 METs |
Running 3 METs |
0.53 |
367 rows × 19 columns
model = exp.create_model('xgboost', train_model=False)
|
|
|
|
|
|
| Initiated |
. . . . . . . . . . . . . . . . . . |
15:55:35 |
| Status |
. . . . . . . . . . . . . . . . . . |
Selecting Estimator |
| Estimator |
. . . . . . . . . . . . . . . . . . |
Extreme Gradient Boosting |
tuned = exp.tune_model(model)
| |
Accuracy |
AUC |
Recall |
Prec. |
F1 |
Kappa |
MCC |
Log Loss |
| Fold |
|
|
|
|
|
|
|
|
| 0 |
0.7209 |
0.9341 |
0.7209 |
0.7212 |
0.7207 |
0.6631 |
0.6632 |
-0.0000 |
| 1 |
0.6047 |
0.8691 |
0.6047 |
0.6133 |
0.6058 |
0.5231 |
0.5244 |
-0.0000 |
| 2 |
0.6860 |
0.9137 |
0.6860 |
0.7059 |
0.6876 |
0.6216 |
0.6246 |
-0.0000 |
| 3 |
0.6395 |
0.9022 |
0.6395 |
0.6478 |
0.6411 |
0.5666 |
0.5675 |
-0.0000 |
| 4 |
0.6163 |
0.8744 |
0.6163 |
0.6211 |
0.6136 |
0.5370 |
0.5388 |
-0.0000 |
| 5 |
0.6353 |
0.8683 |
0.6353 |
0.6386 |
0.6340 |
0.5599 |
0.5609 |
-0.0000 |
| 6 |
0.6941 |
0.9151 |
0.6941 |
0.7027 |
0.6925 |
0.6312 |
0.6334 |
-0.0000 |
| 7 |
0.6588 |
0.9064 |
0.6588 |
0.6642 |
0.6573 |
0.5888 |
0.5904 |
-0.0000 |
| 8 |
0.6235 |
0.8861 |
0.6235 |
0.6374 |
0.6255 |
0.5461 |
0.5474 |
-0.0000 |
| 9 |
0.7529 |
0.9215 |
0.7529 |
0.7611 |
0.7536 |
0.7025 |
0.7037 |
-0.0000 |
| Mean |
0.6632 |
0.8991 |
0.6632 |
0.6713 |
0.6632 |
0.5940 |
0.5954 |
0.0000 |
| Std |
0.0463 |
0.0221 |
0.0463 |
0.0463 |
0.0464 |
0.0559 |
0.0558 |
0.0000 |
Fitting 10 folds for each of 10 candidates, totalling 100 fits
Original model was better than the tuned model, hence it will be returned. NOTE: The display metrics are for the tuned model (not the original one).
# find diff between attributes in model and tuned
[(i, getattr(tuned, i)) for i in set(vars(tuned).keys()) - set(vars(model).keys())]
[('_Booster', <xgboost.core.Booster at 0x161d03eb0>), ('n_classes_', 6)]
from flwr.common import NDArrays
def get_model_parameters(model) -> NDArrays:
"""Returns the parameters of a sklearn LogisticRegression model."""
attrs = [v for v in vars(model)
if v.endswith("_") and not v.startswith("__")]
params = attrs
params += [getattr(model, v) for v in vars(model)
if v.endswith("_") and not v.startswith("__")]
return params
params = get_model_parameters(model)
params
['feature_names_in_',
'n_features_in_',
'n_outputs_',
'classes_',
'n_classes_',
'estimator_',
'estimators_',
array(['age', 'gender', 'height', 'weight', 'steps', 'hear_rate',
'calories', 'distance', 'entropy_heart', 'entropy_setps',
'resting_heart', 'corr_heart_steps', 'norm_heart',
'intensity_karvonen', 'sd_norm_heart', 'steps_times_distance'],
dtype=object),
16,
1,
array([0, 1, 2, 3, 4, 5], dtype=int8),
6,
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=None, splitter='best'),
[DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=1608637542, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=1273642419, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=1935803228, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=787846414, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=996406378, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=1201263687, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=423734972, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=415968276, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=670094950, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=1914837113, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=669991378, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=429389014, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=249467210, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=1972458954, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=1572714583, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=1433267572, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=434285667, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=613608295, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=893664919, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=648061058, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=88409749, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=242285876, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=2018247425, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=953477463, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=1427830251, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=1883569565, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=911989541, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=3344769, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=780932287, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=2114032571, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=787716372, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=504579232, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=1306710475, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=479546681, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=106328085, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=30349564, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=1855189739, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=99052376, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=1250819632, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=106406362, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=480404538, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=1717389822, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=599121577, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=200427519, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=1254751707, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=2034764475, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=1573512143, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=999745294, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=1958805693, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=389151677, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=1224821422, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=508464061, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=857592370, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=1642661739, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=61136438, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=2075460851, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=396917567, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=2004731384, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=199502978, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=1545932260, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=461901618, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=774414982, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=732395540, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=1934879560, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=279394470, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=56972561, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=1927948675, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=1899242072, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=1999874363, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=271820813, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=1324556529, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=1655351289, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=1308306184, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=68574553, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=419498548, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=991681409, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=791274835, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=1035196507, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=1890440558, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=787110843, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=524150214, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=472432043, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=2126768636, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=1431061255, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=147697582, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=744595490, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=1758017741, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=1679592528, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=1111451555, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=782698033, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=698027879, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=1096768899, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=1338788865, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=1826030589, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=86191493, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=893102645, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=200619113, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=290770691, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=793943861, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=134489564, splitter='best')]]
model.get_params()
{'bootstrap': True,
'ccp_alpha': 0.0,
'class_weight': None,
'criterion': 'gini',
'max_depth': None,
'max_features': 'sqrt',
'max_leaf_nodes': None,
'max_samples': None,
'min_impurity_decrease': 0.0,
'min_samples_leaf': 1,
'min_samples_split': 2,
'min_weight_fraction_leaf': 0.0,
'n_estimators': 100,
'n_jobs': -1,
'oob_score': False,
'random_state': 42,
'verbose': 0,
'warm_start': False}
def set_model_params(model, params: NDArrays):
"""Sets the parameters of a sklean model."""
for i in range(0, len(params) // 2):
k, v = params[i], params[i+len(params) // 2]
setattr(model, k, v)
return model
vars(set_model_params(model, params))
{'estimator': DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=None, splitter='best'),
'n_estimators': 100,
'estimator_params': ('criterion',
'max_depth',
'min_samples_split',
'min_samples_leaf',
'min_weight_fraction_leaf',
'max_features',
'max_leaf_nodes',
'min_impurity_decrease',
'random_state',
'ccp_alpha'),
'base_estimator': 'deprecated',
'bootstrap': True,
'oob_score': False,
'n_jobs': -1,
'random_state': 42,
'verbose': 0,
'warm_start': False,
'class_weight': None,
'max_samples': None,
'criterion': 'gini',
'max_depth': None,
'min_samples_split': 2,
'min_samples_leaf': 1,
'min_weight_fraction_leaf': 0.0,
'max_features': 'sqrt',
'max_leaf_nodes': None,
'min_impurity_decrease': 0.0,
'ccp_alpha': 0.0,
'feature_names_in_': array(['age', 'gender', 'height', 'weight', 'steps', 'hear_rate',
'calories', 'distance', 'entropy_heart', 'entropy_setps',
'resting_heart', 'corr_heart_steps', 'norm_heart',
'intensity_karvonen', 'sd_norm_heart', 'steps_times_distance'],
dtype=object),
'n_features_in_': 16,
'n_outputs_': 1,
'classes_': array([0, 1, 2, 3, 4, 5]),
'n_classes_': 6,
'estimator_': DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=None, splitter='best'),
'estimators_': [DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=1608637542, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=1273642419, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=1935803228, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=787846414, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=996406378, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=1201263687, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=423734972, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=415968276, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=670094950, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=1914837113, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=669991378, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=429389014, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=249467210, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=1972458954, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=1572714583, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=1433267572, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=434285667, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=613608295, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=893664919, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=648061058, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=88409749, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=242285876, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=2018247425, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=953477463, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=1427830251, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=1883569565, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=911989541, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=3344769, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=780932287, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=2114032571, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=787716372, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=504579232, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=1306710475, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=479546681, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=106328085, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=30349564, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=1855189739, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=99052376, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=1250819632, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=106406362, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=480404538, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=1717389822, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=599121577, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=200427519, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=1254751707, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=2034764475, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=1573512143, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=999745294, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=1958805693, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=389151677, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=1224821422, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=508464061, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=857592370, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=1642661739, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=61136438, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=2075460851, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=396917567, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=2004731384, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=199502978, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=1545932260, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=461901618, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=774414982, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=732395540, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=1934879560, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=279394470, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=56972561, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=1927948675, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=1899242072, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=1999874363, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=271820813, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=1324556529, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=1655351289, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=1308306184, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=68574553, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=419498548, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=991681409, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=791274835, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=1035196507, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=1890440558, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=787110843, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=524150214, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=472432043, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=2126768636, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=1431061255, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=147697582, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=744595490, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=1758017741, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=1679592528, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=1111451555, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=782698033, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=698027879, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=1096768899, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=1338788865, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=1826030589, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=86191493, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=893102645, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=200619113, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=290770691, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=793943861, splitter='best'),
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=134489564, splitter='best')]}
# random classifier attribut
attrs = ["n_estimators", "max_depth",
"min_samples_split", "min_samples_leaf"]
[getattr(tuned, v) for v in attrs]
[100, None, 2, 1]
unfitted = exp.create_model('rf', train_model=False)
|
|
|
|
|
|
| Initiated |
. . . . . . . . . . . . . . . . . . |
09:36:24 |
| Status |
. . . . . . . . . . . . . . . . . . |
Selecting Estimator |
| Estimator |
. . . . . . . . . . . . . . . . . . |
Random Forest Classifier |
import utils
params = utils.get_model_parameters(best)
params
[[110, 95, 101, 115, 116, 105, 109, 97, 116, 111, 114, 115],
100,
[109,
105,
110,
95,
115,
97,
109,
112,
108,
101,
115,
95,
115,
112,
108,
105,
116],
2,
[109, 105, 110, 95, 115, 97, 109, 112, 108, 101, 115, 95, 108, 101, 97, 102],
1]
# setattr(model, '_label_binarizer', getattr(tuned, '_label_binarizer'))
df = exp.predict_model(model)
| |
Model |
Accuracy |
AUC |
Recall |
Prec. |
F1 |
Kappa |
MCC |
Log Loss |
| 0 |
Random Forest Classifier |
0.8306 |
0.9688 |
0.8306 |
0.8307 |
0.8302 |
0.7961 |
0.7962 |
0 |
from sklearn.utils.validation import check_is_fitted
check_is_fitted(model)
df = exp.pull()
df['Log Loss'], df['Accuracy']
(0 9.362
Name: Log Loss, dtype: float64,
0 0.7403
Name: Accuracy, dtype: float64)
lr.intercept_
array([-8.54252966])
lr.get_params()
{'C': 1.0,
'class_weight': None,
'dual': False,
'fit_intercept': True,
'intercept_scaling': 1,
'l1_ratio': None,
'max_iter': 1000,
'multi_class': 'auto',
'n_jobs': None,
'penalty': 'l2',
'random_state': 42,
'solver': 'lbfgs',
'tol': 0.0001,
'verbose': 0,
'warm_start': False}
# write example for regression
from pycaret.regression import RegressionExperiment
exp1 = RegressionExperiment()
df = get_data('boston')
exp1.setup(data=df, target='medv')
# exp1.add_metric('mae', 'Mean Absolute Error', 'mean_absolute_error', greater_is_better=False)
# exp1.add_metric('r2', 'R^2', 'r2', greater_is_better=True)
# add loss function
best = exp1.compare_models(cross_validation=False)
df = exp1.pull()
df
|
crim |
zn |
indus |
chas |
nox |
rm |
age |
dis |
rad |
tax |
ptratio |
black |
lstat |
medv |
| 0 |
0.00632 |
18.0 |
2.31 |
0 |
0.538 |
6.575 |
65.2 |
4.0900 |
1 |
296 |
15.3 |
396.90 |
4.98 |
24.0 |
| 1 |
0.02731 |
0.0 |
7.07 |
0 |
0.469 |
6.421 |
78.9 |
4.9671 |
2 |
242 |
17.8 |
396.90 |
9.14 |
21.6 |
| 2 |
0.02729 |
0.0 |
7.07 |
0 |
0.469 |
7.185 |
61.1 |
4.9671 |
2 |
242 |
17.8 |
392.83 |
4.03 |
34.7 |
| 3 |
0.03237 |
0.0 |
2.18 |
0 |
0.458 |
6.998 |
45.8 |
6.0622 |
3 |
222 |
18.7 |
394.63 |
2.94 |
33.4 |
| 4 |
0.06905 |
0.0 |
2.18 |
0 |
0.458 |
7.147 |
54.2 |
6.0622 |
3 |
222 |
18.7 |
396.90 |
5.33 |
36.2 |
| |
Description |
Value |
| 0 |
Session id |
2305 |
| 1 |
Target |
medv |
| 2 |
Target type |
Regression |
| 3 |
Original data shape |
(506, 14) |
| 4 |
Transformed data shape |
(506, 14) |
| 5 |
Transformed train set shape |
(354, 14) |
| 6 |
Transformed test set shape |
(152, 14) |
| 7 |
Numeric features |
13 |
| 8 |
Preprocess |
True |
| 9 |
Imputation type |
simple |
| 10 |
Numeric imputation |
mean |
| 11 |
Categorical imputation |
mode |
| 12 |
Fold Generator |
KFold |
| 13 |
Fold Number |
10 |
| 14 |
CPU Jobs |
-1 |
| 15 |
Use GPU |
False |
| 16 |
Log Experiment |
False |
| 17 |
Experiment Name |
reg-default-name |
| 18 |
USI |
5063 |
| |
Model |
MAE |
MSE |
RMSE |
R2 |
RMSLE |
MAPE |
TT (Sec) |
| gbr |
Gradient Boosting Regressor |
2.3513 |
10.5775 |
3.2523 |
0.8816 |
0.1644 |
0.1277 |
0.0700 |
| catboost |
CatBoost Regressor |
2.3582 |
12.1789 |
3.4898 |
0.8637 |
0.1627 |
0.1235 |
0.6200 |
| xgboost |
Extreme Gradient Boosting |
2.4241 |
13.4620 |
3.6691 |
0.8494 |
0.1701 |
0.1275 |
0.1300 |
| rf |
Random Forest Regressor |
2.5463 |
13.5374 |
3.6793 |
0.8485 |
0.1847 |
0.1429 |
0.0800 |
| et |
Extra Trees Regressor |
2.3803 |
13.9484 |
3.7348 |
0.8439 |
0.1726 |
0.1259 |
0.0700 |
| lightgbm |
Light Gradient Boosting Machine |
2.6446 |
15.8780 |
3.9847 |
0.8223 |
0.1942 |
0.1475 |
0.1300 |
| ada |
AdaBoost Regressor |
3.0395 |
18.8047 |
4.3364 |
0.7896 |
0.2177 |
0.1770 |
0.0400 |
| dt |
Decision Tree Regressor |
3.3605 |
23.3951 |
4.8369 |
0.7382 |
0.2098 |
0.1718 |
0.0100 |
| lr |
Linear Regression |
3.7052 |
26.3696 |
5.1351 |
0.7049 |
0.2646 |
0.1875 |
0.0100 |
| lar |
Least Angle Regression |
3.7315 |
26.7222 |
5.1694 |
0.7010 |
0.2645 |
0.1884 |
0.0100 |
| ridge |
Ridge Regression |
3.7410 |
27.0079 |
5.1969 |
0.6978 |
0.2917 |
0.1914 |
0.0100 |
| br |
Bayesian Ridge |
3.7858 |
27.5915 |
5.2528 |
0.6913 |
0.2893 |
0.1957 |
0.0100 |
| en |
Elastic Net |
4.0508 |
31.5715 |
5.6189 |
0.6467 |
0.3107 |
0.2064 |
0.0100 |
| lasso |
Lasso Regression |
4.1660 |
33.2969 |
5.7703 |
0.6274 |
0.3204 |
0.2122 |
0.0000 |
| llar |
Lasso Least Angle Regression |
4.1663 |
33.2995 |
5.7706 |
0.6274 |
0.3206 |
0.2122 |
0.0000 |
| huber |
Huber Regressor |
4.0945 |
34.1371 |
5.8427 |
0.6180 |
0.3113 |
0.2044 |
0.0200 |
| knn |
K Neighbors Regressor |
4.8197 |
45.4761 |
6.7436 |
0.4912 |
0.2721 |
0.2307 |
0.0000 |
| omp |
Orthogonal Matching Pursuit |
6.0011 |
69.8449 |
8.3573 |
0.2185 |
0.3426 |
0.3017 |
0.0100 |
| dummy |
Dummy Regressor |
6.8948 |
89.9663 |
9.4851 |
-0.0067 |
0.4101 |
0.3809 |
0.0000 |
| par |
Passive Aggressive Regressor |
8.6557 |
126.6179 |
11.2525 |
-0.4168 |
0.6046 |
0.3750 |
0.0100 |
|
Model |
MAE |
MSE |
RMSE |
R2 |
RMSLE |
MAPE |
TT (Sec) |
| gbr |
Gradient Boosting Regressor |
2.3513 |
10.5775 |
3.2523 |
0.8816 |
0.1644 |
0.1277 |
0.07 |
| catboost |
CatBoost Regressor |
2.3582 |
12.1789 |
3.4898 |
0.8637 |
0.1627 |
0.1235 |
0.62 |
| xgboost |
Extreme Gradient Boosting |
2.4241 |
13.4620 |
3.6691 |
0.8494 |
0.1701 |
0.1275 |
0.13 |
| rf |
Random Forest Regressor |
2.5463 |
13.5374 |
3.6793 |
0.8485 |
0.1847 |
0.1429 |
0.08 |
| et |
Extra Trees Regressor |
2.3803 |
13.9484 |
3.7348 |
0.8439 |
0.1726 |
0.1259 |
0.07 |
| lightgbm |
Light Gradient Boosting Machine |
2.6446 |
15.8780 |
3.9847 |
0.8223 |
0.1942 |
0.1475 |
0.13 |
| ada |
AdaBoost Regressor |
3.0395 |
18.8047 |
4.3364 |
0.7896 |
0.2177 |
0.1770 |
0.04 |
| dt |
Decision Tree Regressor |
3.3605 |
23.3951 |
4.8369 |
0.7382 |
0.2098 |
0.1718 |
0.01 |
| lr |
Linear Regression |
3.7052 |
26.3696 |
5.1351 |
0.7049 |
0.2646 |
0.1875 |
0.01 |
| lar |
Least Angle Regression |
3.7315 |
26.7222 |
5.1694 |
0.7010 |
0.2645 |
0.1884 |
0.01 |
| ridge |
Ridge Regression |
3.7410 |
27.0079 |
5.1969 |
0.6978 |
0.2917 |
0.1914 |
0.01 |
| br |
Bayesian Ridge |
3.7858 |
27.5915 |
5.2528 |
0.6913 |
0.2893 |
0.1957 |
0.01 |
| en |
Elastic Net |
4.0508 |
31.5715 |
5.6189 |
0.6467 |
0.3107 |
0.2064 |
0.01 |
| lasso |
Lasso Regression |
4.1660 |
33.2969 |
5.7703 |
0.6274 |
0.3204 |
0.2122 |
0.00 |
| llar |
Lasso Least Angle Regression |
4.1663 |
33.2995 |
5.7706 |
0.6274 |
0.3206 |
0.2122 |
0.00 |
| huber |
Huber Regressor |
4.0945 |
34.1371 |
5.8427 |
0.6180 |
0.3113 |
0.2044 |
0.02 |
| knn |
K Neighbors Regressor |
4.8197 |
45.4761 |
6.7436 |
0.4912 |
0.2721 |
0.2307 |
0.00 |
| omp |
Orthogonal Matching Pursuit |
6.0011 |
69.8449 |
8.3573 |
0.2185 |
0.3426 |
0.3017 |
0.01 |
| dummy |
Dummy Regressor |
6.8948 |
89.9663 |
9.4851 |
-0.0067 |
0.4101 |
0.3809 |
0.00 |
| par |
Passive Aggressive Regressor |
8.6557 |
126.6179 |
11.2525 |
-0.4168 |
0.6046 |
0.3750 |
0.01 |
ALLOWED_MODEL = ['lr', 'lf']
# get only allowed indices from df
|
Model |
MAE |
MSE |
RMSE |
R2 |
RMSLE |
MAPE |
TT (Sec) |
# get key value pairs of df where key is df index and value is model name
dfl = df.to_dict()['Model']
dfl.values()
dict_values(['Gradient Boosting Regressor', 'CatBoost Regressor', 'Extreme Gradient Boosting', 'Random Forest Regressor', 'Extra Trees Regressor', 'Light Gradient Boosting Machine', 'AdaBoost Regressor', 'Decision Tree Regressor', 'Linear Regression', 'Least Angle Regression', 'Ridge Regression', 'Bayesian Ridge', 'Elastic Net', 'Lasso Regression', 'Lasso Least Angle Regression', 'Huber Regressor', 'K Neighbors Regressor', 'Orthogonal Matching Pursuit', 'Dummy Regressor', 'Passive Aggressive Regressor'])